2022. 7. 1. 22:40ㆍSpring/개념
스프링은 어떤 종류의 애플리케이션에도 잘 들어맞도록 매우 유연하게 설계된 범용 프레임워크다. 그래서 아키텍처의 종류나 프로젝트를 구성하는 방법에 대한 자유도가 매우 놆다. 그만큼 구성 방법이나 아키텍처를 선택할 때 주의를 기울일 필요가 있다. 스프링이 유연하다고 해서 아무렇게나 가져다 쓰면 스프링이 주는 유익을 제대로 얻지 못할 수도 있기 때문이다.
1 자바 엔터프라이즈 플랫폼과 스프링 애플리케이션
스프링은 주로 자바 엔터프라이즈 환경에서 동작하는 애플리케이션을 개발하는 목적으로 사용된다. 서버에서 동작하는 엔터프라이즈 애플리케이션을 제외한 다른 형태의 애플리케이션에 스프링을 제대로 적용하기 위해서는 SpringRCP 프로젝트나 Spring.ME 같은 추가적인 스프링 지원기술이 필요하다.
자바 엔터프라이즈 애플리케이션은 서버에서 동작하며 클라이언트를 상대로 서비스를 제공하도록 되어 있다. 즉 클라이언트의 요청을 받아서 그에 대한 작업을 수행하고 그 결과를 돌려주는 것이 기본적인 동작 방식이다. 하지만 클라이언트의 요청 없이도 정해진 시간이나 특정 이벤트 발생에 따라 독자적으로 작업을 수행하기도 한다.
1.1 클라이언트와 백엔드 시스템
가장 많이 사용되는 구조는 클라이언트가 웹 브라우저이고 백엔드 시스템이 DB인 구성이다. 간단히 'DB를 사용하는 웹 애플리케이션'이라고 한다. 웹 클라이언트와 DB가 사용되지 않는 시스템은 거의 없으니, 이를 스프링이 사용되는 애플리케이션의 기본 구조라고 생각할 수도 있다. 그런 면에서 스프링의 주요 기능은 웹 브라우저를 클라이언트로 하고 DB에 데이터를 저장, 조회하는 데 집중되어 있다. 그렇다고 해서 꼭 클라이언트는 웹 브라우저여야 하며 백엔드 시스템은 DB를 이용해야 하는것만은 아니다.

1.2 애플리케이션 서버
스프링으로 만든 애플리케이션을 자바 서버환경에 배포하려면 JavaEE 서버가 필요하다. JavaEE 표준을 따르는 애플리케이션 서버는 크게 두 가지로 구분할 수 있다. 하나는 JavaEE의 대부분 표준기술을 지원하고 다양한 형태의 모듈로 배포가 가능한 완전한 웹 애플리케이션 서버(WAS)이고, 다른 하나는 웹 모듈의 배포만 가능한 경량급 WAS 또는 서블릿/JSP 컨테이너다.
- 경량급 WAS / Servlet컨테이너
스프링은 기본적으로 톰캣(tomcat)이나 제티(jetty)같은 가벼운 서플릿 컨테이너만 있어도 충분하다. EJB나 리소스 커넥터, WAS가 제공하는 분산 서비스 등이 굳이 필요하지 않다면 서블릿 컨테이너로도 엔터프라이즈 애플리케이션에 필요한 핵심 기능을 모두 이용할 수 있다. 기존에 EJB와 WAS를 사용해야 가능했던 선언적인 트랜잭션이나 선언적 보안, DB연결 풀링, 리모팅이나 웹 서비스는 물론이고 추가적인 라이브러리의 도움을 받으면 분산/글로벌 트랜잭션까지도 가능하다.
- WAS
고가의 WAS를 사용하면 그만큼 장점이 있다. 성능 면에서는 대단히 낫지 않더라도 미션 크리티컬한 시스템에서 요구하는 고도의 안정성이나 고성능 시스템에서 필수적인 안정적인 리소스 관리, 레거시 시스템의 연동이나 기존 EJB로 개발된 모듈을 함께 사용하는 등의 필요가 있다면 상용 또는 오픈소스 WAS를 이용할 수 있다. 또 WAS는 상대적으로 관리 기능이나 모니터링 기능이 뛰어나서 여러대의 서버를 운영할 때 유리한 점이 많다.
물론 WAS를 사용할 때는 분명한 이유와 근거가 있는지 먼저 충분히 검토해야 한다. 훨씬 가볍고 빠르며 저렴한 비용으로 사용할 수 있는 서블릿 컨테이너로도 대개는 충분한데 특별한 이유도 없이 무겁고 다루기 힘든데다 비싸기까지 한 WAS를 사용할 필요는 없기 때문이다.
- 스프링소스 tcServer
실제로 개발환경과 운영환경에서 가장 많이 사용되는 자바 서버는 웹 모듈만 지원하는 서블릿 컨테이너인 아파치 톰캣이다. 스프링을 개발을 책임지고 있는 기업인 스프링소스에는 아파치 프로젝트인 HTTPD서버와 톰캣 핵심 개발자들이 포진해 있다. 톰캣 전문가인 이들이 중심이 돼서 톰캣을 기반으로 엔터프라이즈 스프링 애플리케이션에 최적화된 경량급 애플리케이션 서버인 tcServer를 개발했다.
대부분의 기능은 사용하지도 않을 고급 WAS를 구매하는 데 비싼 비용을 들이기는 부담스럽고, 그렇다고 운영하고 관리하기 불편한데다 필요할 때 기술지원도 받을 길이 없는 오픈소스 제품인 톰캣을 그대로 사용하기는 불안하다면 tcServer가 좋은 대안이다. tcServer의 가장 큰 장점은 스프링 개발회사가 개발하는 것인 만큼 스프링 애플리케이션 개발과 운영에 꼭 필요한 중요한 기능이 많이 제공된다는 점이다. 개발자 버전이 따로 있어 자유롭게 이용 가능하다. 정식 운영서버에서 사용하고 기술지원을 받으려면 유료로 라이센스를 구매해야 한다.
1.3 스프링 애플리케이션의 배포 단위
- 독립 웹 모듈
스프링은 보통 war로 패키징된 독립 웹 모듈로 배포된다. 톰캣 같은 서블릿 컨테이너를 쓴다면 독립 웹 모듈이 유일한 방법이다. WAS로 배포한다고 하더라도 독립 웹 모듈을 사용하는 경우가 대부분일 것이다. EJB모듈을 함께 상요한다거나 여러개의 웹 모듈을 묶어서 하나의 웹 애플리케이션 모듈로 만들지 않는 한 독립 웹 모듈이 가장 단순하고 편리한 배포 단위다.
- 엔터프라이즈 애플리케이션
경우에 따라선 확장자가 ear인 엔터프라이즈 애플리케이션으로 패키징해서 배포할 수도 있다. 스프링 애플리케이션에서 EJB모듈을 긴밀하게 사용하거나 반대로 EJB모듈에서 스프링으로 만든 애플리케이션을 이용해야 한다면, EJB와 스프링 웹 모듈을 엔터프라이즈 애플리케이션으로 통합해야 한다. 때로는 EJB모듈은 없지만 엔터프라이즈 애플리케이션 배포 방식을 선택하는 경우가 있다. 하나 이상의 웹 모듈과 별도로 분리된 공유 가능한 스프링 컨텍스트를 엔터프라이즈 애플리케이션으로 묶어주는 방법이다.
- 백그라운드 서비스 모듈
이 외에도 J2EE 1.4에서 등장한 rar패키징 방법도 있다. rar는 리소스 커넥터를 만들어 배포할 때 사용하는 방식인데, 만약 스프링으로 만든 애플리케이션이 UI를 가질 필요는 없고 서버 내에서 백그라운드 서비스처럼 동작할 필요가 있다면 rar 모듈로 만들어서 배포할 수 있다. 이때는 J2EE 1.4나 그 이상의 표준을 따르는 WAS가 반드시 필요하다.
운영 플랫폼이나 서버의 종류는 개발 중에라도 언제든지 필요에 따라 언제든지 변경이 가능하다. 어차피 서블릿 컨테이너나 웹 모듈 모두 JavaEE 표준의 일부이기 때문에 설정만 바꾸면 어렵지 않게 이전이 가능하다. 다만 특정 서버환경에서만 제공하는 기능을 사용한다면 변경이 힘들 수도 있다. 장기적으로 서버를 변경하거나 서버의 종류를 바꿀 가능성이 있다면, 서버의 기능에 종속되지 않도록 주의하거나 손쉽게 다른 서버의 기능으로 변경 가능하도록 추상화해서 사용해야 한다.
2. 개발도구와 환경
2.1 JavaSE와 JavaEE
- JavaSE/JDK
스프링 3.0은 JavaSE 5버전에서 추가된 새로운 언어와 문법의 특징을 최대한 활용해서 개발됐기 때문에 기본적으로 JDK 5.0 또는 그 이상을 필요로 한다. 특별한 상황이 아니라면 이미 썬에서 공식지원을 종료해서 수명이 다한 JDK 1.4나 그 이전 환경을 고집할 이유는 없다.
- JavaEE/J2EE
스프링 3.0이 사용될 자바 엔터프라이즈 플랫폼으로는 J2EE 1.4버전이나 JavaEE 5.0이 필요하다.
2.2 IDE
이클립스를 비롯해서 썬에서 직접 만들고 있는 넷빈즈, IntelliJ 등이 대표적인 IDE로 꼽힌다. 모두 자바 엔터프라이즈 개발을 지원하며 스프링 개발을 편하게 도와주는 스프링 지원 기능도 갖고 있다. 따라서 이 중에서 편하고 익숙한 IDE를 골라서 사용하면 된다.
2.3 SpringSource Tool Suite
STS는 최신 이클립스를 기반으로 주요한 스프링 지원 플러그인과 관련 도구를 모아서 스프링 개발에 최적화도도록 만들어진 IDE다. 이클립스와 같이 플러그인 방식을 지원하는 툴을 사용하면 원하는 기능을 필요에 따라 추가할 수 있다는 장점이 있다. 반면에 각 플러그인과 이클립스의 버전을 호환되도록 계속 관리해야 하는 불편한 점도 있다.
SpringIDE 플러그인
스프링 개발에 유용한 기능을 제공하는 플러그인의 모음이다. 스프링 프로젝트와 설정파일 생성 위저드, 편리한 스프링의 XML 설정파일 에디터, 빈의 의존관계 그래프, 네임스페이스 관리 기능 등의 편리한 기능과 도구를 제공한다.
- 빈 클래스 이름 자동완성
- 빈 설정 오류검증 기능
- 프로젝트 생성, 설정파일 생성, 빈 등록 위저드
- 빈 의존관계 그래프
- AOP 적용 대상 표시
- 기타 추가되거나 지원 기능
STS 플러그인
STS 플러그인은 스프링 개발과 설정파일 편집을 지원하는 SpringIDE에 더해서 스프링 애플리케이션의 서버 배치와 같은 추가 기능을 제공해준다. STS는 대부분 최신 JavaEE 서버로의 배치는 물론이고 스프링에 최적화된 애플리케이션 서버인 tcServer 그리고 OSGi플랫폼인 dmServer, 스프링 기반의 클라우드 서비스인 스프링 소스 Cloud Foundry로 배치할 수 있는 기능을 제공해준다.
기타 플러그인
- M2Eclipse
- AJDT(AspectJ Development Tool) : 이클립스에서 AspectJ AOP를 이용한 개발을 지원하는 툴
- VMCI : VMWare 서버 또는 워크스테이션과의 연동을 지원하는 플러그인
- 이클립스 표준 플러그인 : 이클립스 플랫폼에서 제공하는 주요 표준 플로그인으로는 웹개발을 지원하는 WTP, EMP, Mylyn, DSDP 등이 있다.
2.4 라이브러리 관리와 빌드 툴
애플리케이션의 아키텍처를 결정하고 사용 기술을 선정하고 나면 애플리케이션 프로젝트를 IDE에 구성할 차례다. 가장 어려운 부분은 바로 필요한 프레임워크의 모듈과 라이브러리 파일을 선택해서 프로젝트의 빌드 패스에 넣어주는 일이다.
라이브러리 관리의 어려움
스프링으로 애플리케이션을 만들 때 어떤 라이브러리 파일들이 필요할까? 스프링 자체만 해도 20개 가까이 세분화된 JAR모듈이 존재한다. 스프링이 직접 참조하는 필요 라이브러리는 100개가 넘는다. 직접 참조하지 않는 프레임워크나 라이브러리까지 포함하면 스프링으로 만드는 프로젝트에 포함될 가능성이 있는 라이브러리의 종류는 수백여 개에 달할 것이다. 자바의 JAR은 기본적으로 압축 패키징 방법일 뿐 가능한 독립된 모듈이 아니라서 이름이 같으나 구현이 다른 두 클래스 라이브러리 C에 라이브러리 A와 라이브러리 B가 의존하고 있다면 A나 B 둘중에 하나는 비정상적으로 동작할 수도 있다. 그래서 재 패키징을 하거나 스프링에서 직접 재 패키징 한 라이브러리를 써야할 수도 있다. 이렇게 스프링을 이용한 애플리케이션을 만들 때 필요한 라이브러리의 종류와 버전을 적절히 선정하고 개발하면서 추가적으로 필요로 하는 라이브러리를 추가로 하거나 또는 제거하는 등의 관리 작업은 결코 쉬운 일이 아니다.
라이브러리 선정
이미 프로젝트의 기본 틀이 잡혀있고 사용할 라이브러리와 프로젝트 폴더 구조까지 다 결정된 프로젝트에 참여해서 순수한 애플리케이션 개발에만 전념할 수 있다면 이런 걱정은 일단 덜 수 있다. 하지만 자신이 직접 프로젝트를 구성하고 필요한 라이브러리를 선정하거나 추가, 제거하는 등의 관리를 해야 하는 상황이라면 여러모로 신경써야 할 게 많다.
가장 먼저 해야 할 작업은 스프링으로 만드는 애플리케이션에서 정확히 어떤 기능이 필요한지를 정리하는 것이다. 각 기능을 지원하는 기술이 여러 가지 종류가 있다면 그 중에서 어떤 것을 사용할지도 결정해야 한다.
- 스프링 모듈
사용할 기술과 기술 목록이 모두 만들어졌으면 일단 스플이 모듈부터 선정한다. 스프링에는 총 20개의 모듈이 있다. 일부는 거의 모든 애플리케이션에서 공통적으로 사용되는 필수 모듈이다. 그 외의 모듈은 애플리케이션의 아키텍처와 사용 기술에 따라서 선택적으로 적용할 수 있다. 스프링 모듈 사이에서도 의존 관계가 있다. 모듈 사이의 의존관계는 필수와 선택으로 나뉠 수 있다. 예를 들어 A모듈이 의존하는 모듈은 B, C, D가 있다고 하자. 이중 B는 필수이고 C, D는 선택 가능하다면 A를 사용할 때 B는 무조건 추가해주면 되고 C와 D는 A모듈이 가진 기능 중 어떤 것을 사용하느냐에 따라서 필요할 수도 있고 필요 없을 수도 있다. 모듈의 의존관계와 주요 기능을 잘 살펴보고 필수 의존모듈과 선택 의존모듈을 잘 구분해서 선정하자.
- 라이브러리
스프링의 각 모듈은 또 다른 모듈에 의존하기도 하지만 오픈소스 라이브러리 또는 표준 API를 필요로 하기도 하고 경우에 따라서는 상용 제품의 라이브러리에 의존한다. 때로는 각 라이브러리를 활용하는 방법에 따라서 다른 서드파티 라이브러리를 필요로 하는 경우가 있다. 예를 들어 하이버네이트는 스프링 애플리케이션에서 자주 사용되고, 스프링이 직접 지원하고 있기 때문에 스프링의 의존 라이브러리에 속한다. 그런데 하이버네이트 자체를 놓고 보면 다시 세부 기능을 어떻게 사용하느냐에 따라서 또 다른 라이브러리가 필요할 수 있다. 이와 같은 정보는 해당 프레임워크나 라이브러리의 문서를 참조해서 필요한 라이브러리가 어떤 것인지 직접 찾아봐야 한다.
모듈과 라이브러리의 의존관계와 필요한 경우에 대한 설명을 주의 깊게 읽어보고 적용하면 기본적으로 필요한 라이브러리를 선정할 수 있다. 하지만 때로는 어떤 라이브러리를 추가해야 할지 말지 애매한 경우가 있다. 그런 경우에는 어쩔수 없이 시행착오 방법을 이용해야 한다. 이왕이면 어떤 기능을 동작시켰을 때 어떤 클래스와 라이브러리가 필요했는지 기록해두면 나중에 도움이 된다. 단순하고 미련한 방법으로 보이겠지만 스프링 애플리케이션에서 꼭 필요한 라이브러리를 찾는 데 가장 효과적인 방법이다. 인터넷에서 JAR파일을 압축을 풀지 않고 검색하는 방법이나 JAR파일 검색을 지원하는 툴을 찾아 사용해도 좋을 것이다.
필요한 라이브러리가 없으면 애플리케이션이 동작하다가 에러가 나거나 아예 컴파일되지 않는다. 반대로 필요하지 않은 라이브러리가 있을 땐 아무런 문제가 발생하지 않는다. 하지만 불필요한 라이브러리를 추가해두는 것은 또 다른 위험이 있다. 때로는 무작정 모든 라이브러리 파일을 다 추개해놓고 상요하는 개발자도 있다. 그 때문에 애플리케이션 모듈의 파일 크기가 커지는 것은 물론이고 이후에 라이브러리를 관리하는데 심각한 애를 먹을 수도 있다. 때로는 의존 라이브러리의 버전 충돌 문제처럼 풀기 어려운 문제가 발생하기도 한다. 따라서 불필요한 라이브러리는 처음부터 추가하지 않아야 하며, 사용 기술이나 기능이 변경돼서 불필요해진 라이브러리도 바로 제거할 수 있도록 노력해야만 한다.
빌드 툴과 라이브러리 관리
Maven과 ANT는 자바의 대표적인 빌드 툴이다. 빌드 툴은 개발팀이나 조직의 정책 또는 경험에 따라서 결정하면 될 것이고, 여기서는 빌드 툴이 지원하는 의존 라이브러리관리 기능에 대해 얘기해보자. Maven의 특징은 POM이라는 XML파일로 의존 라이브러리를 선언해두기만 하면 원격 서버에서 이를 자동으로 다운로드 받아서 사용할 수 있게 해주는 것이다. Maven의 이런 기능은 매우 매력적이다. 매번 수십 메가에 달하는 라이브러리를 프로젝트 안에 포함시켜서 소스코드와 함께 관리하는 건 부담스러운 일이다. 대신 프로젝트 안에 POM을 통해서 의존 라이브러리 정보만 갖게 하고 필요한 라이브러리는 Maven빌드 과정 중에 자동으로 다운로드 받거나 로컬 공통 리포지토리에서 가져오게 하면 프로젝트 파일의 크기도 줄어둘고 코드 관리도 단순해질 것이다.
이렇게 기술을 중심으로 의존 라이브러리 그룹을 만들어 관리할 수도 있다.
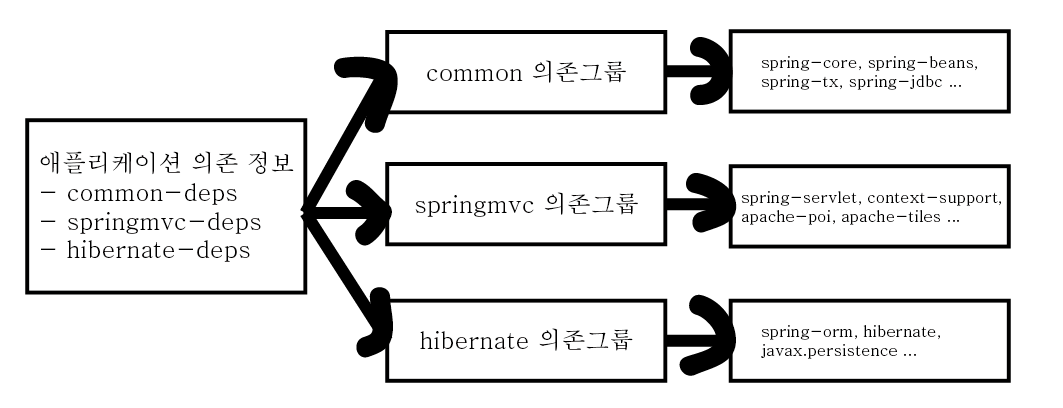
<dependency>
<groupId>com.mycompany.deps</groupId>
<artifactId>commom-deps</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>com.mycompany.deps</groupId>
<artifactId>springmvc-deps</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>com.mycompany.deps</groupId>
<artifactId>hibernate-deps</artifactId>
<version>1.0.0</version>
<type>pom</type>
</dependency>이런 식으로 관리할 수 있다.
스프링의 모듈과 두 가지 이름과 레파지토리
spring-core-3.0.7.RELEASE.jar
org.springframework.core-3.0.7.RELEASE.jar
// 같은 파일이다.두 파일은 동일하지만 배포되는 기술에 따라서 관례적으로 다를 뿐이다. spring-core는 Maven에서 사용하는 명명 규칙을 따른 것이다. Maven은 그룹 아이디와 아티팩트 아이디, 그리고 버전 세 가지로 라이브러리를 정의하는데 그 중에서 아티팩트 아이디와 버전을 조합해서 파일 이름으로 사용한다. 두 번째 org.springframework.core는 OSGi의 모듈 명명 규칙을 따른 것이다. 스프링의 모든 모듈은 OSGi 호환 모듈로 만들어져 있다. 그리고 OSGi 플랫폼에서 사용되지 않는다고 할지라도 OSGi 스타일의 모듈 이름을 사용하도록 권장한다. 그래서 스프링 배포 버전의 dist폴더에 들어 있는 모듈 이름도 모두 OSGi 스타일의 이름이다.
3. 애플리케이션 아키텍처
아키텍처는 여러 가지 방식으로 정의되고 이해될 수 있는 용어다. 가장 단순한 정의를 보자면 어떤 경계 안에 있는 내부 구성요소들이 어떤 책임을 갖고 있고, 어떤 방식으로 서로 관계를 맺고 동작하는지를 규정하는 것이라고 할 수 있다. 아키텍처는 단순히 정적인 구조를 나타내는 것으로만 생각하기 쉽지만 실제로는 그 구조에서 일어나는 동적인 행위와 깊은 관계가 있다.
3.1 계층형 아키텍처
관심, 책임, 성격, 변하는 이유와 방식이 서로 다른 것들을 분리함으로써 분리된 각 요소의 응집도는 높여주고 서로의 결합도를 낮춰줬을 때의 장점과 유익이 뭔지 살펴봤다. 성격이 다른 모듈이 강하게 결합되어 한데 모여 있으면 한 가지 이유로 변경이 일어날 때 그와 상관이 없는 요소도 함께 영향을 받게 된다. 따라서 인터페이스와 같은 유연한 경계를 만들어두고 분리하거나 모아주는 작업이 필요하다.
아키텍처와 SoC
지금까지는 주로 오브젝트 레벨에서 이런 분리의 문제에 대해 생각해봤다. 아키텍처 레벨에서 좀 더 큰 단위에 대해서도 동일하게 적용할 수 있다. 오브젝트를 하나의 모듈 단위라고 생각해보자. 때론 그보다 작은 단위, 예를 들면 하나의 클래스 안에 있는 메소드 레벨에서도 같은 원리를 적용할 수 있다. 심지어 하나의 메소드 안의 코드에도 같은 방식의 접근이 가능하다. 반래도 모듈 단위를 크게 확장해 볼 수도 있다. 애플리케이션을 구성하는 오브젝트들을 비슷한 성격과 책임을 가진 것들끼리 묶는다면 데이터 액세스 로직을 담당하는 DAO를 하나의 단위로 보고 묶거나, 비즈니스 롲기을 구현해놓은 비즈니스 서비스 오브젝트들을 같은 성격으로 묶거나, 웹을 처리하는 코드들을 독자적인 성격으로 분류할 수도 있다.
이런 것들이 성격별로 묶여있지 않다면 난리가 날 것이다. 그래서 성격이 다른 것은 아키텍처 레벨에서 분리해주는 게 좋다. 이렇게 분리된 각 오브젝트는 독자적으로 개발과 테스트가 가능해서 개발과 변경 작업이 모두 빨라질 수 있다. 또 구현 방법이나 세부 로직은 서로 영향을 주지 않고 변경될 수 있을 만큼 유연하다. 전체를 이해하기도 상대적으로 쉽다.
이렇게 책임과 성격이 다른것을 크게 그룹으로 만들어 분리해두는 것을 아키텍처 차원에서는 계층형 아키텍처라고 부른다. 또는 계층이라는 의미를 가진 영어 단어인 티어를 써서 멀티 티어 아키텍처라고도 한다. 보통 웹 기반의 엔터프라이즈 애플리케이션은 일반적으로 세 개의 계층을 갖는다고 해서 3계층 애플리케이션이라고도 한다. 물론 반드시 모든 엔터프라이즈 애플리케이션을 3계층으로 만드는것은 아니다.
3계층 아키텍처와 수직 계층
- 백엔드의 DB나 레거시 시스템과 연동하는 인터페이스 역할을 하는 데이터 액세스 계층
- 비즈니스 로직을 담고 있는 서비스 계층
- 웹 기반의 UI를 만들어내고 그 흐름을 관리하는 프레젠테이션 계층
이렇게 3계층으로 분리한다. 그런데 이 3계층 아키텍처의 각 계층을 부르는 이름은 워낙 다양해서 때론 혼란스러울 수도 있다.
클라이언트 <-> 프레젠테이선 계층 <-> 서비스 계층 <-> 데이터 액세스 계층 <-> DB/레거시
웹 계층 매니저 계층 DAO 계층
UI 계층 비즈니스 로직 계층 EIS 계층
MVC 계층
3계층 아키텍처(텍스트)
- 데이터 액세스 계층
데이터 액세스 계층은 DAO 계층이라고도 불린다. DAO 패턴을 보편적으로 사용하기 때문이다. 또한 데이터 액세스 계층은 DB 외에도 ERP, 레거시 시스템, 메인프레임 등에 접근하는 역할을 하기 때문에 EIS 계층이라고도 한다. 하지만 대개는 장기적인 데이터 저장을 목적으로 하는 DB 이용이 주된 책임이다. 또 외부 시스템을 호출해서 서비스를 이용하는 것은 기반 계층으로 따로 분류하기도 한다.
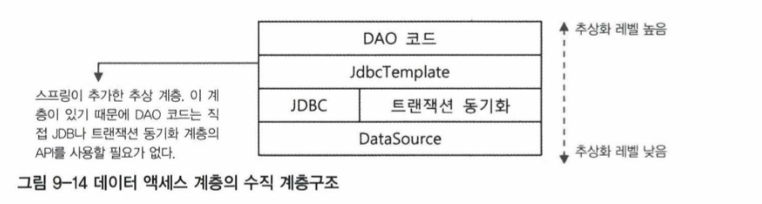
데이터 액세스 계층은 사용 기술에 따라서 다시 세분화된 계층으로 구분될 수 있다. 애플리케이션에서 담당하는 역할에 따라 분류한 3계층 구조와 달리, 데이터 액세스 계층 안에서 다시 세분화하는 경우는 추상화 수준에 따른 구분이기 때문에 수직적인 계층이라고 부르기도 한다. 기본 3계층은 기술 계층보다는 역할에 따라 구분한 것이므로 보통 그림으로 나타낼 때도 가로로 배열한다. 반면에 같은 책임을 가졌지만 추상화 레벨에 따라 구분하는 경우는 세로로 배열해서 표현한다. 스프링의 JdbcTemplate을 사용하는 DAO 계층이라면 그림과 같이 나타낼 수 있다. 이렇게 계층이라는 말은 각각 다른 의미와 상황에서 쓰일 수 있으니 문맥에 맞게 적절한 의미로 이해해야 한다.
추상화 계층은 필요하다면 얼마든지 추가할 수 있다. 만약 JdbcTemplate의 기능과 SqlService의 SQL을 가져오는 기능을 묶어서 더 단순한 방법으로 DAO코드를 작성하고 싶다면 또 하나의 추상 계층을 추가할 수 있다.
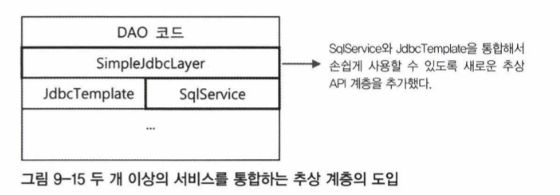
이렇게 새로운 계층을 추가하면 개발자의 애플리케이션 코드에 지대한 영향을 주기 때문에 매우 신중하게 결정해야 한다. 한번 새로운 계층과 API를 만들어 적용하면 이를 최대한 유지할 수 있도록 하위 계층의 변화에 대응해야 하는 책임도 갖게 된다. DAO코드의 사용 패턴을 개발팀 또는 프로젝트 수준에서 잘 분석하고 정리할 수 있다면 새로운 추상 계층의 도입을 고려해볼 만하다. 만약 추상 계층을 새로 추가하는 것은 부담스럽고 경우에 따라서 유연하게 하위 계층의 API를 활용할 필요가 있다면, 공통적인 기능을 분리해서 유틸리티나 헬퍼 메소드 또는 오브젝트로 제공해주는 것도 좋은 방법이다. 이때는 하위 계층과 공통 기능의 사용 방법에 대한 가이드라인이나 코딩 정책이 잘 만들어져서 개발자에게 제공될 필요가 있다.
- 서비스 계층
잘 만들어진 스프링 애플리케이션의 서비스 계층 클래스는 이상적인 POJO로 작성된다. POJO로 만든다면 객체지향적인 설계 기법이 적용된 코드를 통해서 비즈니스 로직의 핵심을 잘 담아내고, 이를 쉽게 테스트하고 유연하게 확장할 수 있다. 서비스 계층은 DAO 계층을 호출하고 이를 활용해서 만들어진다. 때론 데이터 액세스를 위한 기능 외에 서버나 시스템 레벨에서 제공하는 기반 서비스를 활용할 필요도 있다. 예를 들어 웹 서비스와 같은 원격 호출을 통해 정보를 가져오거나 메일 또는 메시징 서비스를 이용하는 것이 대표적인 예다. 이런 기반 서비스는 3계층 어디에서나 접근이 가능하도록 만들 수도 있고, 아키텍처를 설계하기에 따라서 반드시 서비스 계층을 통해 사용되도록 제한할 수도 있다. 코드의 특징과 장단점, 활용 예를 잘 살펴서 결정하면 된다.
서비스 계층은 특별한 경우가 아니라면 추상화 수직 계층구조를 가질 필요가 없다. 단순히 POJO레벨에서 비즈니스 로직을 모델링하다가 상속구조를 만들 수 있을진 몰라도 기술 API를 직접 다루는 코드가 아니기 때문에 기술에 일관된 방식으로 접근하게 하거나 편하게 사용하게 해주는 추상화는 필요 없기 때문이다. 기반 서비스 계층을 사용하는 경우에도 데이터 액세스 계층을 사용하는 경우와 마찬가지로 독립된 계층의 서비스를 이용하는 것으로 봐야 한다. 비즈니스 로직을 담은 서비스 계층과 엔터프라이즈 서비스를 제공하는 기반 서비스 계층은 이름 때문에 혼동되기 쉬우므로 주의하자.
원칙적으로 서비스 계층 코드가 기반 서비스 계층의 구현에 종속되면 안 된다. 서비스 계층의 코드는 추상화된 기반 서비스 인터페이스를 통해서만 접근하도록 만들어서 특정 구현과 기술에 대한 종속성을 제거해야 한다. 또는 AOP를 통해서 서비스 계층의 코드를 침범하지 않고 부가기능을 추가하는 방법을 활용해야 한다.
이상적인 서비스 계층은 백엔드 시스템과 연결되는 데이터 액세스 계층이 바뀌고, 클라이언트와 연결되는 프레젠테이션 계층이 모두 바뀌어도 그대로 유지될 수 있어야 한다. 엔터프라이즈 애플리케이션에서 가장 중요한 자산은 도메인의 핵심 비즈니스 로직이 들어있는 서비스 계층이어야 한다.
- 프레젠테이션 계층
프레젠테이션 계층은 매우 다양한 기술과 프레임워크의 조합을 가질 수 있다. 웹과 프레젠테이션 기술은 끊임없이 발전하고 진보하고 새로운 모델이 등장하기 때문이다. 따라서 프레젠테이션 계층에서 사용할 기술과 구조를 선택하는 일은 간단하지 않다. 엔터프라이즈 애플리케이션의 프레젠테이션 계층은 클라이언트의 종류와 상관없이 HTTP프로토콜을 사용하는 서블릿이 바탕이 된다. HTTP외의 프로토콜을 사용하는 엔터프라이즈 서비스가 전혀 없는 것은 아니지만, 방화벽 문제라든가 통합된 보안의 문제등으로 인해 HTTP로 모두 수렴되는 추세다.
프레젠테이션 계층은 다른 계층과 달리 클라이언트까지 그 범위를 확장될 수도 있다. 초기 클라이언트 모델은 단순히 HTML로 만들어진 결과를 사람이 볼 수 있도록 그려주고, 폼을 통해 입력받은 값을 전달하는 것이었다. 모든 프레젠테이션 로직은 서버의 프레젠테이션 계층의 컴포넌트에서 처리된다. 화면 흐름을 결정하는 것이나 사용자 입력 값에 대한 검증, 서비스 계층의 호출과 전달되는 값의 포맷의 변화, 뷰라고 불리는 화면을 어떻게 그릴지에 대한 로직 등이 모두 서버에서 처리됐다. 이때의 클라이언트는 단순히 서버 프레젠테이션 계층의 기능에 대한 사용자 인터페이스에 불과했다. 하지만 최근에는 점점 많은 프레젠테이션 로직이 클라이언트로 이동하고 있다.
스프링은 웹 기반의 프레젠테이션 계층을 개발할 수 있는 전용 웹 프레임워크를 제공한다. 동시에 스프링은 다양한 서드파티 웹 기술을 지원하기도 한다. 아예 프레젠테이션 계층을 통째로 스프링이 아닌 다른 웹 기술을 가져다 사용할 수도 있다. 스프링이 애플리케이션에 적용할 수 없는 웹 기술은 없다고 봐도 좋다.
계층형 아키텍처 설계의 원칙
오브젝트와 그 관계에 적용했던 대부분의 객체지향 설계의 원칙은 아키텍처 레벨의 계층과 그 관계에도 동일하게 적용할 수 있어야 한다. 각 계층은 응집도가 높으면서 다른 계층과는 낮은 결합도를 유지할 수 있어야 한다. 각 계층은 자신의 계층의 책임에만 충실해야 한다. 데이터 액세스 계층은 데이터 액세스에 관한 모든 것을 스스로 처리해야 한다. 데이터 액세스 계층에 비즈니스 로직을 담거나 웹 파라미터를 파싱하는 코드나 결과를 화면에 어떻게 뿌릴지 결정하는 코드가 들어간다면 응집도가 낮아진다. 결과적으로 변화에 대한 유연성이 떨어지고 이해하기 힘든 코드를 가진 계층이 되고 말 것이다. 각 계층은 자신의 역할에만 충실해야 하고 자신과 관련된 기술이 아닌 다른 기술 API의 사용을 삼가해야 한다.
종종 실수하는 계층간 설계의 예를 살펴보자. 다음은 서비스 계층이 DAO를 호출할때 사용하도록 정의한 인터페이스 메소드다.
public ResultSet findUserByName(String name) throws SQLException;문제점을 살펴보자면
- 데이터 액세스 계층의 기술과 그 역할을 다른 계층에 노출한다.
- SQLException이라는 JDBC 기술 종속적인 예외를, 그것도 체크 예외로 던져버리면, 이를 사용하는 서비스 계층에서는 SQLException을 해석해서 예외상황을 분석하고 이를 처리하는 코드를 만들어야한다. (JDBC에 종속되버린다.)
public List<User> findUserByName(String name) throws DataAccessException;이런 코드는 유연성이 떨어지기 때문에 이렇게 바꿔야한다.
또, 흔히 저지르는 실수 중의 하나는 프레젠테이션 계층의 오브젝트를 그대로 서비스 계층으로 전달하는 것이다. 서블릿의 HttpServletRequest나 HttpServletResponse, HttpSession같은 타입을 서비스 계층 인터페이스 메소드의 파라미터 타입으로 사용하면 안 된다. 계층의 경계를 넘어갈 때는 반드시 특정 계층에 종속되지 않는 오브젝트 형태로 변환해줘야 한다.
만일 서비스 계층의 코드에 웹 프레젠테이션 계층의 기술을 노출했다고 해보자. 웹 방식의 클라이언트가 아닌 다른 시스템에서 요청을 받아서 처리해야 하는 경우에는 웹 기술에 종속된 코드는 재사용이 불가능해진다. 같은 로직을 가졌지만 클라이언트의 종류에 따라서 비즈니스 로직 코드가 달라지는 결과를 초래할 수도 있다.
어떤 경우에라도 계층 사이의 낮은 결합도를 깨트리지 않도록 설계해야 한다. 당연히 계층 사이의 호출은 인터페이스를 통해 이뤄져야 한다. 인터페이스를 하나 더 만드는 것이 번거롭다고 그냥 클래스를 이용해서는 안 된다. 인터페이스를 사용하게 한다는 건 각 계층의 경계를 넘어서 들어오는 요청을 명확히 정의하겠다는 의미다. 여기서 말하는 인터페이스란 단지 자바의 interface 키워드를 사용하라는 의미가 아니다. 인터페이스에 아무 생각없이 클래스의 모든 public 메소드를 추가한다면 인터페이스를 사용하는 가치가 떨어진다. 한번 정의돼서 다른 계층에서 사용하기 시작한 인터페이스 메소드는 변경이 매우 까다롭고 비용이 많이 든다. 따라서 매우 신중하게 결정해야 하며 계층 내부의 예상되는 변화에도 쉽게 바뀌지 않도록 주의해서 만들어야 한다. 당연히 다른 계층에서 꼭 필요한 메소드만 노출해야 한다.
스프링의 DI는 기본적으로 오브젝트 사이의 관계를 다룬다. 따라서 계층 사이의 경계나 그 관계에 직접적으로 관여하지 않는다. 하지만 모든 경계에는 오브젝트가 존재하고 그 사이의 관계도 오브젝트 대 오브젝트로 정의되기 마련이다. 그런 면에서 스프링의 DI가 계층 사이의 관계에도 적용된다고 볼 수 있다.
하지만 DI는 계층을 구분해주지 않기 때문에 빈 사이의 의존관계를 만들 때 주의해야 한다. 한 계층의 내부에서만 사용되도록 만든 빈 오브젝트가 있는데, 이를 DIㄹ르 통해 다른 계층에서 함부로 가져다 쓰는 일은 피해야 한다는 말이다. 또 중간 계층을 건너뛰어서 관계를 갖지 않는 계층의 빈을 직접 DI 하지 않도록 주의해야 한다.
3.2 애플리케이션 정보 아키텍처
엔터프라이즈 시스템은 본질적으로 동시에 많은 작업이 빠르게 수행돼야 하는 시스템이다. 사용자의 작업 상태를 오래 유지할 수 있는 독립 애플리케이션과 달리 엔터프라이즈 애플리케이션은 일반적으로 사용자의 요청을 처리하는 동안만 간단한 상태를 유지한다. 애플리케이션의 주요 상태정보는 주로 DB나 메인프레임 같은 EIS백엔드 시스템에 저장된다. 하나의 업무 작업이 여러 번의 요청과 페이지에 걸쳐 일어나는 경우에 유지돼야 하는 임시 상태정보는 클라이언트에 일시적으로 보관되기도 하고 서버의 사용자별 세션 메모리에 저장되기도 한다.
이렇게 애플리케이션을 사이에 두고 흘러다니는 정보를 어떤 식으로 다룰지를 결정하는 일도 아키텍처를 결정할 때 매우 중요한 기준이 된다. 엔터프라이즈 애플리케이션에 존재하는 정보를 단순히 데이터로 다루는 경우와 오브젝트로 다루는 경우, 두 가지 기준으로 구분해볼 수 있다.
데이터 중심 아키텍처는 애플리케이션에 흘러다니는 정보를 단순히 값이나 값을 담기 위한 목적의 오브젝트 형태로 취급하는 구조다. DB나 백엔드 시스템에서 가져온 정보를 값으로 다루고 그 값을 취급하는 코드를 만들어 로직을 구현하고 값을 그대로 프레젠테이션 계층의 뷰, 즉 사용자가 보는 화면과 연결해주는 것이다.
이런 방식은 객체지향 기술이나 언어를 사용하지 않던 시절의 엔터프라이즈 애플리케이션과 크게 다를 바 없다. 데이터 중심 설계의 특징은 비즈니스 로직이 DB 내부의 저장 프로시저나 SQL에 담겨있는 경우가 많다는 점이다. 보통 DB에서 돌려주는 내용을 그대로 맵이나 단순 결과 저장용 오브젝트에 넣어서 전달한다. DB 결과 값을 사용하는 일부 비즈니스 로직이 서비스 계층에 존재하기도 하고, 아무런 가공 없이 그대로 프레젠테이션 계층에 전달되어 사용자에게 보이기도 한다.
데이터 중심 아키텍처는 핵심 비즈니스 로직을 어디에 많이 두는지에 따라서 DB에 무게를 두는 구조와 서비스 계층의 코드에 무게를 두는 구조로 구분할 수 있다.
DB/SQL 중심의 로직 구현 방식
데이터 중심 구조의 특징은 하나의 업무 트랜잭션에 모든 계층의 코드가 종속되는 경향이 있다는 점이다. 예를 들어 사용자의 이름으로 사용자 정보를 검색해서 일치하는 사용자의 아이디, 비밀번호, 이름, 가입일자만을 보여주는 작업이 있다고 하자. 이것이 하나의 업무 단위가 되면 모든 계층의 코드가 이 기준에 맞춰서 만들어진다. 사용자 조회라는 단위 업무를 위해서만 존재하는 각 계층의 코드가 만들어진다는 뜻이다.
검색조건은 SQL로 만들어진다. 사용자 정보를 웹 페이지에 나타낼 때 가입일자 중에서 연도만 보여줘야 한다면, 가입일자 필드에서 연도를 추출하는 것은 SQL의 날짜처리 펑션을 이용해야 한다. 그래야 SQL의 결과를 그대로 웹 페이지의 정보 필드에 1:1로 매핑해서 넣어줄 수 있기 때문이다. 결국 SQL은 이미 화면에 어떤식으로 출력이 될지 알고있는 셈이다.
SQL의 결과는 컬럼 이름을 키로 갖는 맵에 저장되거나 조회 페이지에 필요한 네 가지 정보를 담을 수 있는 단순한 오브젝트를 저장돼서 전달된다. 서비스 계층은 별로 할 일이 없다. 프레젠테이션 계층의 JSP뷰는 DAO의 SQL에서 정확히 어떤 필드 값을 리턴할지, 어떤 포맷으로 전달할지 알고 있다. SQL의 SELECT절에 나오는 컬럼 이름을 그대로 사용해서 전달된 맵이나 결과를 저장하는 오브젝트에서 값을 가져와 화면에 출력한다. 만약 새로운 필드가 추가되거나 DB 테이블의 컬럼 이름이 변경됐다면, 그에 따라서 맵이나 오브젝트에 저장될 엔트리 또는 프로퍼티 이름이 바뀌거나 추가될 것이고 그에 맞게 뷰의 내용도 변경된다.
모든 계층의 코드는 '이름을 이용한 고객 조회'라는 업무에 종속된다. 또한 업무의 내용이 바뀌면 모든 계층의 코드가 함께 변경된다. 종속적일 뿐 아니라 배타적이어서 다른 단위 업무에 재사용되기 힘들다. 유사한 방법의 사용자 조회용 DAO 메소드라도 화면에 나타날 정보가 다르면 SQL이 달라지기 때문에 새로 만들어야 한다.
너무 길어서 정리하자면, 이런식의 데이터베이스/SQL 중심의 로직 구현 방식은 개발하기는 쉬우나 SQL에 종속되기때문에 자바 코드를 단지 DB와 웹 화면을 연결해주는 단순한 인터페이스 도구로 전락시키는 것이다. 자바의 오브젝트는 단지 HTTP 서비스 채널을 만들어주고 JDBC를 이용해 DB기능을 사용하게 하는 스크립트 정도로 역할을 축소시킨다. 그리고 이 방식은 변화에 매우 취약하다. 객체지향의 장점이 별로 활용되지 못하는데다 각 계층의 코드가 긴밀하게 연결되어 있기 때문이다. 중복을 제거하기도 쉽지 않다. 업무 트랜잭션에 따라 필드 하나가 달라져도 거의 비슷한 DAO 메소드를 새로 만들기도 한다. 또한 로직을 DB와 SQL에 많이 담으면 담을수록 점점 확장성이 떨어진다. 잘 작성된 복잡한 SQL 하나가 수백 라인의 자바 코드가 필요한 비즈니스 로직을 한번에 처리할 수도 있다. 하지만 과연 바람직한 것일까? 이런 복잡한 SQL을 누구나 쉽게 이해하고 필요에 따라 유연하게 변경할 수 있을까? 또 복잡한 SQL을 처리하기 위해서 제한된 자원인 DB에 큰 부담을 주는 게 과연 바람직한 일인지 생각해볼 필요가 있다.
로직을 DB보다는 애플리케이션으로 가져오는 편이 유리한 점이 많다. 그리고 SQL이나 저장 프로시저에 담긴 로직은 테스트하기 힘들다. 반면에 오브젝트에 담긴 로직은 간단히 검증할 수 있다. 또한 요즘 유행하는 객체지향 분석과 모델링의 결과로 나온 모델을 쉽게 가져다 쉽게 오브젝트로 만들어낼 수 있다. 따라서 DB에는 부하를 가능한 한 주지 않는 간단한 작업만 하고 복잡한 로직은 오브젝트에 담아서 애플리케이션 내에서 처리하도록 만드는 편이 낫다.
단지 익숙하고 편하다는 이유로 스프링 애플리케이션 개발에도 여전히 DB 중심의 아키텍처를 선택한다면 스프링의 장점을 제대로 누릴 수 있는 기회를 얻지 못할 것이 분명하다.
거대한 서비스 계층 방식
DB에 많은 로직을 두는 개발 방법의 단점을 피하면서 애플리케이션 코드의 비중을 높이는 방법이 있다. DB에는 부하가 걸리지 않도록 저장 프로시저의 사용을 자제하고 복잡한 SQL을 피하면서, 주요 로직은 서비스 계층의 코드에서 처리하도록 만드는 것이다. 여전히 SQL의 결과를 그대로 담고 있는 단순한 오브젝트 또는 맵을 이용해 데이터를 주고 받는다. 대신 많은 비즈니스 로직을 DB의 저장 프로시저나 SQL에서 서비스 계층의 오브젝트로 옮겨왔기 때문에 애플리케이션 코드의 비중이 커진다. 그만큼 구조는 단순해지고 객체지향 개발의 장점을 살릴 기회가 많아진다.
비즈니스 로직을 DB나 SQL에 담는 경우에는 항상 최종 결과만 DAO에서 서비스 계층으로 전달된다. 반면에 거대 서비스 계층 방식에서는 DAO에서 좀 더 단순한 결과를 돌려준다. DAO가 돌려준 정보를 분석, 가공하면서 비즈니스 로직을 적용하는 것은 서비스 계층 코드의 책임이 된다. DAO와 SQL은 상대적으로 단순해지고, 그중 일부는 여러 서비스 계층 코드에서 재사용이 가능해진다.
비즈니스 로직이 복잡해지면 서비스 계층의 코드도 매우 복잡해지고 커진다. 업무 트랜잭션 단위로 서비스 계층의 메소드가 만들어질 가능성이 높은데, 그러다 보면 하나의 메소드가 매우 거대해지기도 한다. 이를 여러 메소드로 분산시킨다면 메소드 크기는 상대적으로 줄겠지만 전체 클래스 코드의 양은 그대로다. 상대적으로 단순한 DAO 로직을 사용하고, 비즈니스 로직의 대부분을 서비스 계층에 집중하는 이런 접근 방법은 결국 거대한 서비스 계층을 만들게 된다. 데이터의 분석, 처리와 함께 비즈니스 로직의 대부분이 서비스 계층 코드에 집중되기 때문이다. 서비스 계층의 코드는 여전히 업무 트랜잭션 단위로 집중돼서 만들어지기 때문에 DAO를 공유할 수 있는 것을 제외하면 코드의 중복도 적지 않게 발생한다.
데이터 액세스 계층이나 DB는 비즈니스 로직을 직접 담고 있지 않기 때문에 이전보다 훨씬 가벼워진다. 대신 DB가 돌려주는 데이터를 가지고 비즈니스 로직을 구현하는 서비스 계층이 매우 두터워진다.
거대 서비스 계층 방식의 장점은 애플리케이션의 코드에 비즈니스 로직이 담겨 있기 때문에 자바 언어의 장점을 활용해 로직을 구현할 수 있고 테스트하기도 수월하다는 점이다. 또한 DAO가 다루는 SQL이 복잡하지 않고 프레젠테이션 계층의 뷰와 1:1로 매핑되지 않아도 되기 때문에 일부 DAO 코드는 여러 비즈니스 로직을 공유해서 사용할 수 있다.
하지만 데이터 액세스 계층의 SQL은 서비스 계층의 비즈니스 로직에 따라 만들어지기 쉽다. 그래서 계층 간의 결합도가 여전히 크다. 서비스 계층의 메소드는 크기가 큰 업무 트랜잭션 단위로 만들어지기 때문에 비슷한 기능의 코드가 여러 메소드에서 중복돼서 나타나기 쉽다. 자주 사용되는 세부 로직을 추출해서 공통 기능으로 뽑아내는 일도 불가능하진 않지만 일반화하기는 힘들다. 그 이유는 DAO가 제공해주는 값의 포맷에 따라 이를 취급하는 방법이 달라지기 때문이다.
각 단위 업무별로 독립적인 개발이 가능하므로 초기 개발 속도가 빠르고, 개발자 사이에 간섭 없이 독립적인 개발이 가능하다는 장점이 있다. 또한 핵심 로직이 자바 코드 안에 담겨져 있으므로 테스트하기가 상대적으로 수월하다. 하지만 본격적인 객체지향 설계가 힘들고, 개발자나 개개인의 코딩 습관이나 실력에 따라서 비슷한 로직이더라도 전혀 다른 스타일의 코드가 나오기 십상이다.
데이터 중심 아키텍처의 특징은 계층 사이의 결합도가 높은 편이고 응집도는 떨어진다는 점이다. 화면을 중심으로 하는 업무 트랜잭션 단위로 코드가 모이기 때문에 처음엔 개발하기 편하지만 중복이 많아지기 쉽고 장기적으로 코드를 관리하고 발전시키기 힘들다는 단점이 있다.
3.3 오브젝트 중심 아키텍처
오브젝트 중심 아키텍처가 데이터 중심 아키텍처와 다른 가장 큰 특징은 도메인 모델을 반영하는 오브젝트 구조를 만들어두고 그것을 각 계층 사이에서 정보를 전송하는 데 사용한다는 것이다. 그래서 오브젝트 중심 아키텍처는 객체지향 분석과 모델링의 결과로 나오는 도메인 모델을 오브젝트 모델로 활용한다. 대개 도메인 모델은 DB의 엔티티 설계에도 반영되기 때문에 관계형 DB의 엔티티 구조와도 유사한 형태일 가능성이 높다. 물론 DB에는 없지만 비즈니스 로직에만 존재하는 모델도 있기 때문에 항상 일치하는 것은 아니다. 이렇게 오브젝트를 만들어두고 오브젝트 구조 안에 정보를 담아서 각 계층 사이에 전달하게 만드는 것이 오브젝트 중심 아키텍처다.
데이터와 오브젝트
카테고리와 상품이라는 두 가지 엔티기가 나온다고 해보자. 카테고리 하나에는 여러 개의 상품이 포함된다. 각 상품은 하나의 카테고리에 소속된다. 전형적인 1:N의 관계다.
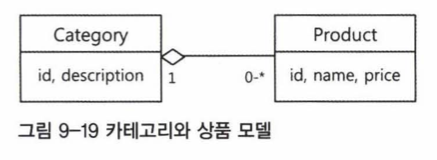
이를 DB 테이블로 만들면
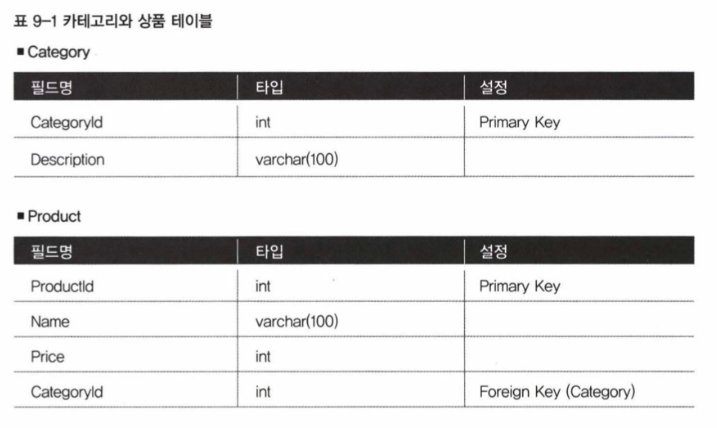
SQL과 DB의 관점에서 생각한다면, DAO 에서는 다음과 같이 SQL을 사용해 만들것이고, SQL의 실행 결과는 맵이나 배열에 담을것이다.
select c.categoryid, c.description, p.productid, p.name, p.price from product p
join category c on p.categoryid = c.category id배열에 담으려면 인덱스별로 필드 이름을 일일이 기억해야 하기 때문에 불편하다. 배열 대신 맵에 필드 이름과 값을 함께 담고 맵의 리스트를 만들어 돌려주는게 편리하다. DAO에서는 JDBC로 SQL을 실행하고 받은 결과를 코드와 같이 담아서 서비스 계층으로 넘겨줄 것이다.
while(rs.next()) {
Map<String, Object> resMap = new HashMap<String, Object>();
resMap.put("categoryid", rs.getString(1));
resMap.put("description", rs.getString(2));
...
list.add(resMap);
}하지만 이런 방식은 코드에서 무엇을 하는지 알 수 없고, DAO에서 SQL을 변경하거나 필드 개수나 순서, 이름을 바꾼다면 서비스 계층과 프레젠테이션 계층의 이름도 같이 변경해야 한다. 반면에 오브젝트 방식에서는 애플리케이션에서 사용되는 정보가 도메인 모델의 구조를 반영해서 오브젝트 안에 담긴다. 도메인 모델은 전 계층에서 동일한 의미를 갖는다. 따라서 도메인 모델이 반영된 도메인 오브젝트도 전 계층에서 일관된 구조를 유지한 채로 사용할 수 있다. SQL이나 웹 페이지의 출력 포맷, 입력 폼 등에 종속되지 않는 일관된 형식의 애플리케이션의 정보를 다룰 수 있게 된다.
먼저 도메인 모델의 구조를 따라서 의미있는 타입과 정보를 가진 클래스를 정의한다.
public class Category{
int categoryid;
String description;
Set<Product> products;
// 접근자, 수정자
...
}
public class Product {
int productid;
String name;
int price;
Category category;
// 접근자, 수정자
...
}이 구조는 단순히 특정 SQL에 대응되는 맵과 배열, 매번 달라지는 SQL 결과를 담기 위해 급조해서 만든 오브젝트와는 달리, 애플리케이션 어디에서도 사용될 수 있는 일관된 형식의 도메인 정보를 담고 있다. DB에서 SQL 결과로 가져온 값을 그대로 사용하는 경우와는 다르게, 도메인 모델을 반영하는 오브젝트를 사용하면 자바 언어의 특성을 최대한 활용할 수 있도록 정보를 가공할 수 있다. 대표적으로 오브젝트 사이의 관계를 나타내는 방법을 들 수 있다. 자바에는 관계하고 있는 다른 오브젝트와 직접 연결하는 방법이 있다. 레퍼런스 변수를 잉요해서 다른 오브젝트를 참조하는 것이다. 하나 이상의 오브젝트와 관계를 가지려면 컬렉션을 이용할 수도 있다.
자바에서는 레퍼런스 변수를 통한 상호 참조가 가능하기 때문에 원한다면 Category 오브젝트에서 다음과 같은 코드로 Category에 속한 Product를 간단히 가져올 수 있다.
Set<Product> products = myCategory.getProducts();
// 이런식으로 레퍼런스 변수를 통해 참조가 가능하다.데이터 중심 방식에서는 Category와 그에 대응되는 Product를 찾아 SQL을 이용해 조인한 다음 하나의 맵에 몽뚱그려서 가져왔다. 반면에 오브젝트 중심 방식에서는 테이블의 정보와 그 관계를 유지한 채로 정확한 개수의 Category 오브젝트와 그에 대응되는 Product 오브젝트로 만들어서 사용한다. 따라서 테이블이 Category가 한개이고, 그에 대응되는 Product열이 5개라면, 오브젝트도 하나의 Category오브젝트와 이에 연결된 5개의 Product가 만들어질 것이다. 이 두 가지 오브젝트는 레퍼런스 변수를 통해 서로 연결되어 있기 때문에 메소드 파라미터나 리턴 값으로 전달할 때 Category 오브젝트 하나를 전달하더라도 그에 연결된 Product 5개가 함께 전달된다. 반대로 Product의 컬렉션을 전달해도 된다. 어차피 레퍼런스를 따라가면 서로 참조할 수 있기 때문이다.
이렇게 도메인 모델을 따르는 오브젝트 구조를 만들려면 DB에서 가져온 데이터를 도메인 오브젝트 구조에 맞게 변환해줄 필요가 있다. 한번 변화되면 그 이후는 수월해진다. DAO는 자신이 DB에서 가져와서 도메인 모델 오브젝트에 담아주는 정보가 어떤 업무 트랜잭션에서 어떻게 사용될지는 신경 쓰지 않아도 된다. 서비스 계층 또한 DAO에서 어떤 SQL을 사용했는지는 몰라도 된다. Category와 Product 정보를 두개의 SQL로 나눠서 가져왔든, 하나의 SQL로 조인해서 가져왔든 상관없다. 서비스 계층에서 필요한 정보를 조건에 맞게 조회해서 도메인 모델 오브젝트 형태로 돌려주는 DAO를 이용하기만 하면 된다. 그리고 가져온 도메인 오브젝트에 담긴 정보를 활용해서 비즈니스 로직을 처리하면 된다. 어떤 DAO가 사용됐고, 어떤 비즈니스 로직을 거쳤는지에 관해선 프레젠테이션 계층은 알 필요가 없다. 자신에게 전달된 도메인 오브젝트를 활용해서 필요한 정보를 화면에 출력하기만 하면 된다.
도메인 오브젝트를 사용하는 코드
어떤 카테고리에 포함된 상품의 모든 가격을 계산해야 하는 로직이 필요하다면 서비스 계층의 오브젝트 안에 메소드를 만들어 사용하면 된다. 어떤 DAO를 이용해서 Category를 가져왔는지는 중요하지 않다. 조건을 가지고 Category를 하나 검색했을 수도 있고, 모든 Category 목록을 가져왔을 수도 있다. 어떻게든 Category 오브젝트를 갖고있다면 calcTotalOfProductPrice() 메소드를 호출해서 카테고리에 담긴 모든 상품 가격의 합을 계산할 수 있다.
public int calcTotalOfProductPrice(Category cate) {
int sum = 0;
for(Product prd : cate.getProducts()) {
sum += prd.getPrice();
}
}도메인 모델을 알고 있다면 메소드가 무슨 작업을 하는지 이해하기 어렵지 않다. 테스트를 만들어 검증하기도 간단하고, 로직이 변경될 때 코드를 수정하기도 수월하다. Category 자체가 독립된 오브젝트이므로 서비스 계층 어디에서든지 Category의 상품 가격을 계산해야 할 때는 이 메소드를 사용하면 된다. Category 내의 상품 가격을 계산하는 코드가 여러 개의 업무 트랜잭션에서 필요하다고 해도 코드의 중복이 일어나지 않을 수 있다.
오브젝트 구조로 정보를 갖고 있으면 어떤 식으로든 활용하기 편리하다. 자바에서는 '.'을 이용해 레퍼런스 변수를 따라가면 관련된 정보를 손쉽게 이용할 수 있다. Product 오브젝트가 하나 주어졌을 때, 해당 Product의 Category에는 상품이 모두 몇개가 있는지 알고싶다면 다음과 같이 간단한 코드를 사용할 수 있다.
int count = product.getCategory().getProducts().size();만약 SQL을 이용해 Product와 Category를 조인해서 통째로 가져왔다면, 적지않은 if문을 사용해야만 이와 기능이 동일한 코드를 만들 수 있다. 테스트를 만드는 편리함 면에서도 큰 차이가 있다. SQL에 담긴 로직을 테스트하는 건 복잡하고 불편하다. 반면에 도메인 오브젝트를 사용하는 코드는 간단히 테스트 값을 담은 도메인 오브젝트를 생성해서 쉽게 검증할 수 있다.
도메인 오브젝트 사용의 문제점
일관된 의미를 가지고 유연하며 애플리케이션 전반에 공유 가능한 도메인 모델을 따르는 오브젝트로 정보를 다루면 많은 장점이 많다. 코드는 이해하기 쉽고 로직을 작성하기도 수월하다. 프레젠테이션 영역에서도 이미 정의된 도메인 오브젝트 구조만 알고 있다면 아직 DAO가 작성되지 않았어도 뷰를 미리 만들 수도 있다. 코드의 재사용성은 높아지고 DAO는 더 작고 효율적으로 만들어질 수 있다.
하지만 단점도 있다. 최적화된 SQL을 매번 만들어 사용하는 경우에 비해 성능면에서 조금은 손해를 감수해야 할 수도 있다. DAO는 비지니스 로직의 사용 방식을 알지 못하므로, 도메인 오브젝트의 모든 필드 값을 다 채워서 전달하는 경우가 대부분이다. 그런데 하나의 오브젝트에 담긴 필드의 개수가 많아지다 보면 그중에는 드물게 사용되는 필드도 있을 수 있다. 어떤 비지니스 로직에서 필요한 정보가 몇 개의 필드뿐이라면 DAO에서 도메인 오브젝트의 모든 필드 정보를 채워서 전달하는 것은 낭비일 수도 있다. 비즈니스 로직에 따라서 필요한 정보가 달라질 수 있기 때문에 발생하는 문제다.
오브젝트 관계에도 문제가 있다. 만약 단순히 Product 정보만 필요한 비즈니스 로직이 있다고 해보자. 그런데 DAO가 돌려준 Product 오브젝트에는 관계를 갖고 있는 Category 오브젝트도 함께 담겨 있을 것이다. Category에 담긴 정보까지 사용될 때도 있겠지만, 어떤 경우에는 Product에 담긴 정보만 필요할 때도 있다. 그럼에도 Category오브젝트까지 다 조회해서 오브젝트로 만들어서 가져오는 것은 상당한 낭비다.
물론 Product 정보를 가져올 때 Category가 필요한 경우와 그렇지 않은 경우를 구분해서 DAO를 만들어줄 수 있다. 하지만 문제는 DAO에서 Product만 가져오게 하면 Product의 category 필드에는 null 값이 들어간다는 점이다. 불필요한 오브젝트를 생성하는 일을 피할 수 있어서 좋기는 한데, 자칫 비지니스 로직 코드를 작성하다가 그런 사실을 깜박하고 product의 category 필드를 사용할 경우 예상치 못한 널포인트를 만날 수도 있다. 결국 최적화를 고려해서 DAO를 작성하려면 DAO는 비즈니스 로직에서 각 오브젝트를 어디까지 사용해야 하는지 어느 정도 알고 있어야 한다. 그래서 데이터 중심 접근 방법의 단점이라고 봤던, DAO와 비즈니스 로직 코드의 결합도가 높아지는 문제가 발생할 수도 있다. 프레젠테이션 계층에서도 마찬가지다. Product오브젝트를 전달받아서 Product 내의 필드 값만 사용할 수도 있고 연결된 Category의 정보까지 출력할 수도 있기 때문이다.
이런 문제를 해결하는 접근 방법은 여러 가지가 있다.
- 지연된 로딩 기법을 이용한다.
- JPA나 JDO, 하이버네이트, TopLink와 같은 오브젝트/ RDB 매핑 기술을 사용한다.
도메인 오브젝트를 사용하는 오브젝트 중심 아키텍처에서는 가능하다면 ORM과 같은 오브젝트 중심 데이터 액세스 기술을 사용하는 것을 권장한다. 사용하기 쉽고 직관적이며 코드의 양도 대폭 줄기 때문이다. 다양한 기법을 이용하면 SQL을 직접 만들어 쓰는 경우에 못지않게 성능을 향상시킬 수 있다.
ORM을 사용하지 않고 JDBC를 이용하는 경우라면 지연된 로딩 기법을 제공하는 코드를 추가해주거나, 사용되는 필드의 종류와 사용되는 관련 오브젝트의 범위에 따라서 여러 개의 DAO메소드를 만들어 사용해야 할 수도 있다. 이 경우 DAO 코드나 도메인 오브젝트 코드의 중복이 일부 발생하고 계층 사이의 결합도도 증가될 수는 있지만, 데이터 중심 아키텍처에 비하면 미미한 정도다.
오브젝트 중심의 아키텍처는 도메인 모델을 따르는 오브젝트를 사용해 각 계층 사이에 정보를 전달하고, 이를 이용해 비즈니스 로직이나 프레젠테이션 로직을 작성한다. 계층 간의 결합도는 낮아지고 일관된 정보 모델을 사용하기 때문에 개발 생산성과 코드의 품질, 테스트 편의성도 향상시킬 수 있다.
그런데 도메인 오브젝트는 자바오브젝트다. 오브젝트는 원래 데이터를 저장하기 위해서만 사용하는 것이 아니다. 내부의 정보를 이용하는 기능도 함께 갖고 있어야 한다. 클래스는 속성과 행위의 조합이다. 필드와 그에 대한 접근자, 수정자만 갖고 있는 오브젝트는 반쪽짜리다. 물론 도메인 모델을 반영하는 오브젝트 구조에 정보를 담는 것만으로도 많은 장점이 있지만, 이 정도에서 도메인 오브젝트의 사용을 제한할 필요는 없다. 가능하다면 이를 더 적극적으로 활용하게 만들어야 한다.
오브젝트 중심 아키텍처는 오브젝트의 활용 방법을 기준으로 다시 구분해볼 수 있다.
빈약한 도메인 오브젝트 방식
도메인 오브젝트에 정보만 담겨있고, 정보를 활용하는 아무런 기능도 갖고 있지 않다면 이는 온전한 오브젝트라고 보기 힘들다. 그래서 이런 오브젝트를 빈약한 오브젝트라고 부른다. 물론 이렇게라도 도메인 모델을 반영한 오브젝트의 정보를 담아 활용하는 편이 도메인 오브젝트를 전혀 사용하지 않는 것보다는 훨씬 낫다. 계층 사이의 독립성을 확보하기 위해서는 특정 계층에 종속되지 않으면서 애플리케이션 전반에서 사용될 수 있는 정보를 담은 오브젝트가 필요하기 마련이고, 그래서 이런 빈약한 도메인 오브젝트 방식도 실제로 많이 사용된다.
아마도 스프링을 사용하는 개발자가 흔히 사용하는 방식인 이 빈약한 도메인 오브젝트 방식이 아닐까 싶다. 다른 스프링 핵심 개발자들이 쓴 전문서적인 Professional Srping-Framework라는 책에서도 이 빈약한 도메인 오브젝트 방식을 사용했다. 오브젝트 자체는 복잡한 도메인 모델을 따라서 잘 만들어져 있고 이 구조를 그대로 모든 계층이 활용하고 있기 때문에 깔끔하고 유연한 코드로 만들어져 있다. 하지만 도메인 오브젝트는 데이터를 저장해두는 것 외에는 아무런 기능이 없다.
도메인 오브젝트에 넣을 수 있는 기능은 뭐가 있을까? 도메인 모델을 반영해서 만들어진 도메인 오브젝트이니 그 기능이라고 하면 도메인의 비즈니스 로직이라고 볼 수 있다. 그렇다면 빈약한 도메인 오브젝트 방식에서는 비즈니스 로직이 어디에 존재할까? 바로 서비스 계층이다. 사실 다루는 정보의 구조가 다를 뿐이지 빈약한 도메인 오브젝트 방식은 데이터 중심 아키텍처의 거대 서비스 계층구조와 비슷하다. 빈약한 오브젝트 방식도 거대 서비스 계층 방식의 하나라고 보면 된다. 도메인 오브젝트는 3개의 계층에는 독립적으로 존재하면서 일관된 구조의 정보를 담아서 계층 간에 전달하는 데 사용된다.
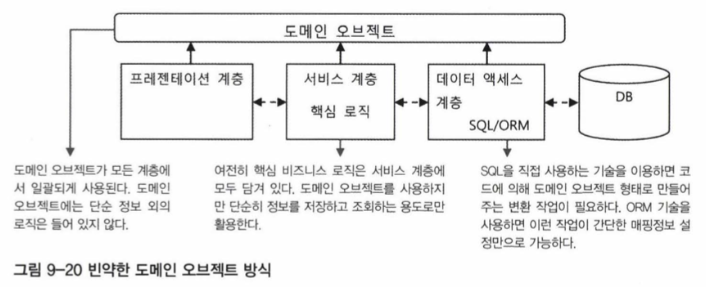
빈약한 도메인 오브젝트 방식의 한계는 거대 서비스 계층 방식과 유사하다. 비록 도메인 오브젝트라는 일관된 오브젝트를 활용하기 때문에 SQL에 의존적인 데이터 방식 보다는 훨씬 유연하고 간결하지만, 여전히 서비스 계층의 메소드에 대부분 비즈니스 로직이 들어 있기 때문에 로직의 재사용성이 떨어지고 중복의 문제가 발생하기 쉽다.
하지만 비즈니스 로직이 복잡하지 않다면 가장 만들기 쉽고 3계층 구조의 특징을 잘 살려서 개발할 수 있는 유용한 아키텍처다.
풍성한 도메인 오브젝트 방식
풍성한 도메인 오브젝트 또는 영리한 도메인 오브젝트 방식은 빈약한 오브젝트의 단점을 극복하고 도메인 오브젝트의 객체지향적인 특징을 잘 사용할 수 있도록 개선한 것이다. 어떤 비즈니스 로직은 특정 도메인 오브젝트나 그 관련 오브젝트가 가진 정보와 깊은 관계가 있다. 이런 로직을 서비스 계층의 코드가 아니라 도메인 오브젝트에 넣어주고, 서비스 계층의 비즈니스 로직에서 재사용하게 만드는 것이다.
앞에서 서비스 계층의 코드로 만들었던 calcTotalOfProductPrice()는 Category라는 오브젝트와 그 관련 Product의 정보만을 사용하는 간단한 로직이다. 이것을 굳이 서비스 계층의 메소드에 별도로 만들지 않고 Category클래스의 메소드에 넣을 수도 있다.
public class Category {
...
List<Product> products;
public int calcTotalOfProductPrice() {
int sum = 0;
for(Product prd : this.products()) {
sum += prd.getPrice();
}
return sum;
}
}이렇게 도메인 오브젝트 안에 로직을 담아두면 이 로직을 서비스 계층의 메소드에 따로 만드는 경우보다 응집도가 높다. 데이터와 그것을 사용하는 기능이 한곳에 모여 있기 때문이다. 만약 Category에 대해 상품 가격을 계산하는 작업이 CategoryService외의 서비스 계층 오브젝트에서 필요하다면, 그때마다 Cateogry 오브젝트를 파라미터로 해서 CategoryService의 메소드를 호출하는 것은 번거롭다. CategoryService를 사용하기 위해 DI도 해줘야 한다. 다른 모듈의 비즈니스 로직을 작성하고 있는 개발자는 Category 안에 그런 기능이 있는지 몰라서 같은 기능을 가진 코드를 스스로 만들어 쓸지도 모른다.
현재 재고에 대한 비즈니스 로직을 담고 있는 InventoryService가 있다고 하자. 여기서 특정 카테고리의 상품에 대한 현재 가격의 합을 계산할 필요가 생겼다. 그리고 혹시 미리 만들어둔 관련 기능이 있는지 CategoryService를 뒤져보고 거기서 calcTotalOfProductPrice(Category c) 메소드를 찾았다고 하자. 그러면 이 기능을 사용하기 위해 InventoryService에 CategoryService를 DI 해줘야 한다. 그렇게 주입받은 CategoryService를 호출해서 그 메소드를 이용해야 한다. 그나마 같은 기능의 코드를 중복하지 않고 최적화해서 이미 만들어진 비즈니스 로직을 재활용하는 것인데도 제법 번거로울 수 있다.
public class InventorySerivce{
private CategorySerivce categoryService;
// 수정자 주입 메소드, 다른 서비스 오브젝트에 담긴 로직을 사용하기 위해 DI 해줘야 한다.
public void setCategorySerivce ...
public void complexInventoryAnalysis() {
...
int total this.categoryService.calcTotalOfProductPrice(category);
// 계산 로직에서 사용될 정보를 가진 category를 파라미터로 전달해야 한다.
...
}
}이런식으로 여러 개의 도메인 오브젝트에 대한 로직을 사용해야 하는 복잡한 코드라면 각 비즈니스 로직을 담고 있는 서비스 오브젝트를 DI해서 로직을 담은 메소드를 호출해야 한다. 이미 정보를 담고 있는 오브젝트가 있지만, 그 정보를 다루는 메소드는 별개의 서비스 오브젝트에 분리되어 있기 때문이다.
그런데 Category에 대한 계산 로직을 Category안에 넣어뒀다면 이런 번거로운 작업이 필요가 없다! 그냥 Category 오브젝트에게 직접 필요한 계산을 시키면 되는것이다. CategoryService를 DI할 필요도 없다. 비슷한 코드가 여기저기 비즈니스 로직에 중복돼서 나타나지도 않는다. 특정 도메인 오브젝트에 종속되는 비즈니스 로직은 서비스 계층의 오브젝트가 아니라 도메인 오브젝트 안에 넣으면 된다. 이제 InventoryService의 코드는 불필요한 DI없이 간결하게 만들 수 있다.
public class InventoryService {
public void complexInventoryAnalysis() {
...
int total = category.calcTotalOfProductPrice();
// 서비스 계층의 메소들르 사용하는 코드보다 훨신 간결하다. 직관적이다.
// 무엇보다도 객체지향적이다.
...
}
}풍성한 도메인 오브젝트 방식은 도메인 오브젝트를 사용한다는 면에서 빈약한 오브젝트 방식과 비슷하지만, 실제 작성된 코드를 살펴보면 훨씬 간결하고 객체지향적이라는 사실을 알 수 있다. 객체지향 분석과 설계를 통해 만들어진 도메인 모델의 정보를 정적인 구조뿐 아니라 동적인 동작 방식에도 적극 활용할 수 있다. 그렇다고해서 서비스 계층 오브젝트가 필요 없어지는건 아니다. 도메인 오브젝트 안에 메소드로 들어가는 로직들은 대부분 해당 오브젝트나, 긴밀한 연관관계를 맺고 있는 관련 오브젝트의 정보와 기능만을 활용한다. 여러 종류의 도메인 오브젝트의 기능을 조합해서 복잡한 비즈니스 로직을 만들었다면 특정 도메인 오브젝트에 넣기는 힘들다. 이런 비즈니스 로직은 서비스 계층의 오브젝트에 두는 것이 적당하다.
도메인 오브젝트는 직접 데이터 액세스 계층이나 기반 계층 또는 다른 서비스 계층의 오브젝트에 접근할 수 없기 때문에 서비스 계층이 필요하기도 하다. 대개는 비즈니스 로직을 처리하는 중에 DB에 담긴 정보를 가져와서 활용하거나 결과를 다시 DB나 외부 시스템에 전송하는 등의 작업이 필요하다. 그러려면 서비스 계층의 오브젝트와 같이 DAO 오브젝트를 DI 받아서 사용할 수 있어야 한다. 하지만 도메인 오브젝트는 그럴 수 없다.
왜 도메인 오브젝트는 DAO 오브젝트를 DI받을 수 없을까? 그것은 도메인 오브젝트는 스프링 컨테이너가 관리하는 오브젝트, 즉 빈이 아니기 때문이다. 서비스 계층의 오브젝트나 데이터 액세스 계층의 오브젝트는 모두 스프링 빈으로 등록되기 때문에 필요에 따라 서로 DI 할 수 있다. DI를 받으려면 자신도 역시 스프링 컨테이너에서 관리되는 빈이어야 한다. 그런데 도메인 오브젝트는 스프링의 빈이 아니다. 도메인 오브젝트는 애플리케이션의 코드 또는 기타 프레임워크나 라이브러리, JDBC 템플릿 등에 의해 필요할 때마다 새롭게 만들어진다. 따라서 스프링이 생성하거나 관리하는 오브젝트가 아니므로 DI를 받을 수 없다. 결국 이런 도메인 오브젝트는 DAO나 서비스 오브젝트 같은 스프링 빈의 기능을 사용할 수 없다.
그래서 수식 계산이나 조건에 따른 데이터의 변경 또는 자신이 가진 정보에 대한 분석 같은 도메인 오브젝트 자신에 국한된 로직은 도메인 오브젝트 안에 추가할 수 있지만, 그 결과를 DB에 저장하거나 메일로 발송하거나 DB를 검색해서 원하는 정보를 가져와 활용하는 작업은 도메인 오브젝트에서 불가능하다. 그래서 DAO와 기반계층 오브젝트를 DI받아 사용할 수 있는 서비스 계층의 코드가 필요하다.
서비스 계층은 도메인 오브젝트를 DB나 외부 리소스에서 가져오고 변경된 정보나 새로 등록된 정보를 DB에 반영하는 등의 작업과 함께 도메인 오브젝트가 갖고 있는 기능이 있다면 이를 활용해서 비즈니스 로직을 처리해야 한다.
스프링의 빈으로 관리되는 3계층의 오브젝트들은 도메인 오브젝트를 자유롭게 이용할 수 있지만 그 반대는 안 된다는 사실을 주의해야 한다.
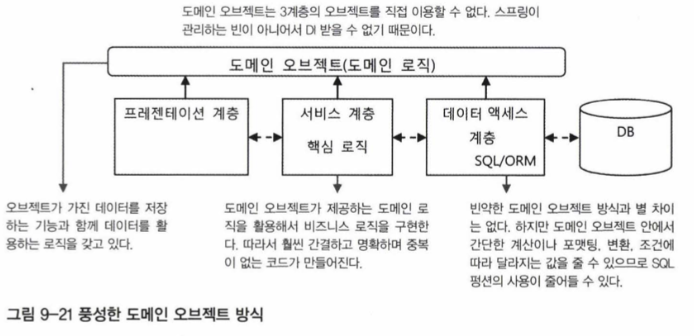
풍성한 도메인 오브젝트 방싱근 빈약한 도메인 오브젝트 방식보다 서비스 계층의 코드가 간결하다. 비즈니스 로직 코드를 이해하기도 쉽다. 따라서 빈약한 도메인 오브젝트를 피하고 도메인 오브젝트가 스스로 처리 가능한 기능과 도메인 비즈니스 로직을 갖도록 만드는 것이 바람직하다.
충실한 도메인 모델링과 도메인 오브젝트 개발이 선행되고 그 내용이 개발자에게 사전에 충분히 공유되지 않았다면 차라리 데이터 구조만 오브젝트 방식으로 정의 해놓은 빈약한 도메인 오브젝트 방식이 혼란을 피할 수 있고 쉽게 접근할 수 있는 대안이 될 수도 있다. 하지만 처음은 쉬워도 시간이 지나고 시스템이 복잡해지면 빈약한 도메인 오브젝트 방식의 단점이 드러날 것은 각오해야 한다.
도메인 계층 방식
지금까지 살펴본 바로는 도메인 모델을 따르는 오브젝트를 만들고 이를 활용하는 방법에는 한계가 있다. 도메인 오브젝트에 담을 수 있는 비즈니스 로직은 데이터 액세스 계층에서 가져온 내부 데이터를 분석하거나, 조건에 따라 오브젝트 정보를 변경, 생성하는 정도에 그칠 수밖에 없다. 이렇게 변경된 정보가 다시 DB 등에 반영되려면 서비스 계층 오브젝트의 부가적인 작업이 필요하다.
도메인 오브젝트가 스스로 필요한 정보는 DAO를 통해 가져올 수 있고, 생성이나 변경이 일어났을 때 직접 DAO에게 변경사항을 반영해달라고 요청할 수는 없을까? DAO외에도 다양한 기반계층의 서비스를 이용하도록 할 방법은 없을까? 만약 도메인 오브젝트가 기존 3계층의 오브젝트를 DI 받아서 직접 이용할 수 있게 된다면 어떤 일이 일어날까?
도메인 계층의 역할과 비중을 극대화하려다 보면 기존의 풍성한 도메인 오브젝트 방식으로는 만족할 수 없다. 그래서 등장한 것이 바로 도메인 오브젝트가 기존 3계층과 같은 레벨로 격상되어 하나의 계층을 이루게 하는 도메인 계층 방식이다. 개념은 간단하다. 도메인 오브젝트들이 하나의 독립적인 계층을 이뤄서 서비스 계층과 데이터 액세스 계층의 사이가 존재하게 하는 것이다.
도메인 오브젝트가 독립된 계층을 이뤘기 때문에 기존 방식과는 다른 두 가지 특징을 갖게 된다.
- 첫째는 도메인에 종속적인 비즈니스 로직의 처리는 서비스 계층이 아니라 도메인 계층의 오브젝트 안에서 진행된다는 점이다.
서비스 계층에서 사용자가 입력한 정보를 바탕으로 새로운 도메인 오브젝트를 만들었든 데이터 액세스 계층을 통해 도메인 오브젝트를 가져왔든 상관없이 도메인 오브젝트에게 비즈니스 로직의 처리를 요청할 수 있다. 해당 도메인 오브젝트를 중심으로 만들어진 로직이라면 그 이후의 작업은 도메인 오브젝트와 그 관련 오브젝트 사이에서 진행된다. 일단 도메인 계층으로 들어가면 서비스 계층의 도움 없이도 비즈니스 로직의 대부분의 작업을 수행할 수 있다는 뜻이다.
- 두번째 특징은 도메인 오브젝트가 기존 데이터 액세스 계층이나 기반 계층의 기능을 직접 활용할 수 있다는 것이다.
그런데 앞에서 도메인 오브젝트는 스프링에 등록돼서 싱글톤으로 관리되는 빈이 아니기 때문에 다른 빈을 DI받을 수 없다고 했다. 그렇다면 도메인 계층의 도메인 오브젝트들은 어떻게 다른 빈을 이용할 수 있을까? 물론 방법은 DI다. 여전히 도메인 오브젝트는 스프링이 직접 만들고 관리하는 오브젝트, 즉 빈이 아니다. 하지만 이런 스프링이 관리하지 않은 오브젝트에도 DI를 적용할 수 있다. 물론 그에 따른 간단한 설정이 추가돼야 한다.
스프링이 관리하지 않는 도메인 오브젝트에 DI를 적용하기 위해선 AOP가 필요하다. 물론 스프링 AOP는 부가기능을 추가할 수 있는 위치가 메소드 호출 과정으로 한정되고 AOP의 적용 대상도 스프링의 빈 오브젝트뿐이다. 하지만 스프링 AOP 대신 AspectJ AOP를 사용하면 클래스의 생성자가 호출되면서 오브젝트가 만들어지는 시점을 조인 포인트로 사용할 수 있고 스프링 빈이 아닌 일반 오브젝트에도 AOP 부가기능을 적용할 수 있다. 이 부가기능은 오브젝트의 수정자 메소드나 DI용 애노테이션을 참고해서 DI 가능한 대상을 스프링 컨테이너에서 찾아 DI 해주는 기능이다. 스프링이 직접 관리하지 않는 오브젝트에 대한 DI 서비스가 일종의 AOP 부가기능으로 도메인 오브젝트에 적용될 수 있다.
이 방법을 이용하면 도메인 오브젝트가 만들어질 때 스프링의 빈 오브젝트를 DI 받게 할 수 있다. 결국 도메인 오브젝트가 데이터 액세스 계층이나 기반 계층의 오브젝트를 이용하도록 만들 수 있다. 이 덕분에 도메인 오브젝트 기능의 제약이 사라진다. 물론 도메인 오브젝트에 담긴 기능은 자신과 관련 오브젝트에 대한 작업으로 한정돼야 한다.
도메인 계층 방식은 이전의 어떤 방식보다 도메인 오브젝트에 많은 비즈니스 로직을 담아낼 수 있다. 그럼에도 서비스 계층의 역할이 완전히 사라지는 건 아니다. 때로는 여러 도메인 오브젝트의 기능을 조합해서 복잡한 작업을 진행해야 하는 경우가 있다. 특정 도메인 오브젝트에 담길 수 없는 이런 작업은 서비스 계층에서 도메인 계층과 협력을 통해 진행하는 것이 바람직하다. 또는 굳이 도메인 계층을 거치지 않고 바로 데이터 액세스 계층으로부터 정보를 가져와 클라이언트에 제공해야 하는 경우도 있다. 이럴 때도 서비스 계층이 인터페이스 역할을 담당한다. 또 트랜잭션 경계를 설정하거나 특정 도메인 로직에 포함되지는 않지만 애플리케이션에서 필요로 하는 기반 서비스를 이용해야 하는 작업을 위해서라도 서비스 계층은 필요하다.
대신 서비스 계층의 비중과 규모는 단순히 오브젝트를 사용하는 방식에 비해 훨씬 작다. 복잡하지 않은 애플리케이션에서는 아예 서비스 계층을 제거하고 모든 비즈니스 로직을 도메인 오브젝트에 담을 수도 있다. 이때는 트랜잭션 경계가 프레젠테이션 계층에서 최초로 호출되는 도메인 오브젝트의 메소드에 설정돼야 한다.
도메인 오브젝트를 독립적인 계층으로 만들려고 할 때 고려해야 할 중요한 사항이 있다. 도메인 오브젝트가 도메인 계층을 벗어나서도 사용되게 할지 말지 결정해야 한다. 도메인 오브젝트가 계층을 이루기 전에는 모든 계층을 걸쳐 사용되는 일종의 정보 전달 도구 같은 역할을 했다. 하지만 독자적인 계층을 이뤘을 때는 상황이 달라질 수 있다.
선택할 수 있는 방법은 두 가지가 있다.
- 첫째, 여전히 모든 계층에서 도메인 오브젝트를 사용한다. 도메인 계층은 물론이고 서비스 계층이나 그 앞의 프레젠테이션 계층, 화면 출력을 위한 뷰에서도 직접 도메인 오브젝트를 전달받아 사용할 수 있게 하는 것이다.
도메인 오브젝트를 이용해 도메인 로직을 적용하면 도메인 계층에서 진행되지만, 그 결과를 DB에 반영할 때나 화면에 출력하거나 페이지 이동을 위한 정보로 활용하기 위해 프레젠테이션 계층에서 참조할 때도 도메인 오브젝트를 사용할 수 있다. 따라서 도메인 모델을 따르는 오브젝트 구조를 활용하는 면에서 오브젝트 중심 아키텍처의 장점을 그대로 누릴 수 있다.
하지만 주의하지 않으면 심각한 혼란을 초래할 수 있다. 도메인 오브젝트의 메소드는 이제 단순한 값의 조작이나 분석, 변환 정도가 아니라 중요한 도메인/비즈니스 로직을 담당하고 있다. 심지어 DB나 백엔드 시스템에 작업 결과를 반영할 수도 있다. 그런데 문제는 도메인 프로젝트를 프레젠테이션 계층이나 뷰 등에서 사용하게 해주면 이를 함부로 사용하는 위험이 뒤따를 수 있다. JSP로 뷰를 만드는 개발자가 도메인 오브젝트가 담은 정보를 가져와 화면을 출력하는 데만 사용하는 것이 아니라, 중요한 비즈니스 로직을 담은 메소드를 함부로 호출한다면 심각한 문제가 일어날 수도 있다. 오브젝트를 넘겨받은 이상 그것을 사용하는 데 제약이 없기 때문에 함부로 조작하거나 기능을 실행해버릴 위험이 있다.
이런 문제를 피하는 방법은 철저한 개발 가이드라인을 만들어두고 이를 강력하게 적용한다. 예를 들어 프레젠테이션 계층에서는 도메인 오브젝트를 전달받아 접근자를 사용해서 정보를 가져오는 경우와 폼의 결과를 반영할 새로운 도메인 오브젝트를 만들어 수정자를 호출하는 경우 외에는 다른 메소드를 사용하지 않는다는 개발 정책을 만들어두는 것이다.
이런 규정을 어기는 개발자가 있을수도 있다. 코딩 정책의 적용을 분석할 수 있는 툴을 이용해 검증하거나 AspectJ의 정책/표준 강제화 기능을 사용하면 된다. 간단한 포인트컷 표현식만으로 특정 계층의 오브젝트가 사용할 수 있는 메소드의 범위를 제한하는 등의 정책 강제화 작업을 간단하게 해낼 수 있다.
- 두번 째, 도메인 오브젝트는 도메인 계층을 벗어나지 못하게 한다. 도메인 계층 밖으로 전달될 때는 별도로 준비된 정보 전달용오브젝트에 도메인 오브젝트의 내용을 복사해서 넘겨줘야 한다. 이런 오브젝트는 데이터 전달을 위해 DTO(Data Transfer Object)라고 불린다. DTO는 상태의 변화를 허용하지 않고 읽기전용으로 만들어지기도 한다. 반대로 사용자가 등록한 값이나 외부 시스템으로부터 전달받은 정보를 도메인 계층으로 전달하는 경우에도 DTO를 이용할 수 있다.
DTO는 기능을 갖지 않으므로 사용하기 안전하다. 또 도메인 오브젝트를 외부 계층의 코드로부터 보호해준다. 반면에 도메인 오브젝트와 비슷한 구조를 가진 오브젝트를 따로 만들어야 하고 이를 매번 변환해줘야 하는 번거로움이 있다. 따라서 AOP와 같은 방법을 이용해 변환을 자동으로 해주도록 만들 필요가 있다.
뭐가 더 낫다고 말하는건 힘들지만, DTO를 기존에 이용했던 사람이라면 후자도 괜찮을 것이다. 번거로운 작업을 최소하하고 대신 표준 개발 정책을 잘 따라서 개발하도록 개발팀을 관리할 수 있다면 전자의 방법이 편하다!
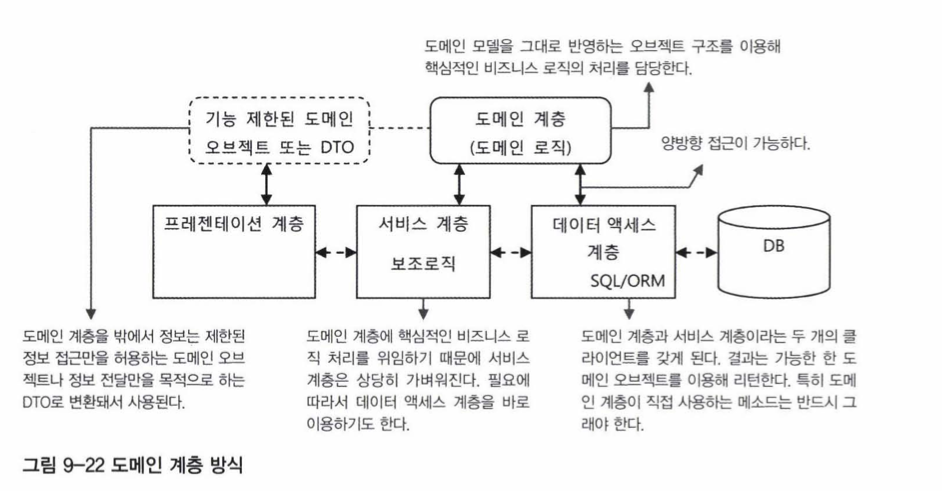
도메인 계층은 기존 3계층과 비슷한 수준에서 독립적인 역할을 담당하고 있긴 하지만 그 특성은 확연히 다르다. 서비스를 제공하는 싱글톤으로 계속 존재하는 다른 계층의 오브젝트와 달리, 도메인 계층의 오브젝트는 매우 짧은 시간 동안만 존재했다가 사라지는 것을 반복한다. 각 사용자의 요청별로 독립적으로 도메인 계층을 이루는 오브젝트들이 생성됐다가 해당 요청을 처리하고 나면 버려진다. 때론 하나의 복잡한 작업 흐름을 따라서 오래 존재하는 경우도 있지만 여전히 그 생명주기는 짧다. 도메인 오브젝트는 사용자별 요청에 대해 독립적인 상태를 유지하고 있어야 하기 때문이다. 상태정보를 담고 있기 때문에 여러 스레드가 공유하는 싱글톤이 될 수가 없다. 또 DAO나 컨트롤러, 또는 스프링 외의 라이브러리를 통해 오브젝트가 만들어지는 경우가 많기 때문에 스프링이 관리하는 빈으로 등록조차 불가능하다. 그렇기 때문에 특별한 방법으로 DI를 해줘야지만 다른 3계층의 빈들과 협력해서 일을 처리할 수 있다.
이런 여러 가지 제약과 불편을 감수하면서라도 이 방식을 택해야 하는 경우는 매우 복잡하고 변경이 잦은 도메인을 가졌을 때다. 복잡한 도메인의 구조와 로직을 최대한 도메인 계층의 오브젝트에 반영하고, 도메인 모델과 설계에 변경이 발생했을 때 도메인 계층의 오브젝트도 빠르게 대응해서 변경해주기 위해서다. 도메인 계층은 응집도가 매우 높기 때문에 단위 테스트를 작성하기 편하다. DAO나 외부 서비스 오브젝트와 연동할 때도 도메인 오브젝트 타입을 유지할 수 있기 때문에 목 오브젝트 등을 이용해 단위 테스트로 만들기도 쉽다. 도메인이 가진 복잡함을 객체지향적인 설계의 모든 장점을 동원해서 가장 유연한 방법으로 대응할 수 있다.
반면에 그만큼 복잡하지 않은 애플리케이션이라면 이런 방식을 선택하는 것 자체가 오히려 과도한 부담을 줄 수도 있다.
따라서 도메인 계층을 이용하는 방식을 선택할 때는, 오브젝트 중심 아키텍처의 기본 두 가지 방법을 충분히 경험해보고 오브젝트 중심의 개발 방식에 익숙해진 뒤에 조심스럽게 접근해야 한다.
DTO와 리포트 쿼리
오브젝트 중심 아키텍처는 애프리케이션 내의 모든 정보를 항상 도메인 오브젝트에 담아야하는가? 꼭 그렇지는 않다.
도메인 계층 방식의 경우 도메인 계층을 벗어난 정보를 DTO라 불리는 특정 계층에 종속되지 않는 정보 전달의 목적을 가진 단순 오브젝트에 담아 사용하기도 한다. 그외의 방법에서도 DTO의 사용이 꼭 필요할 때가 있다.
대표적인 예는 리포트 쿼리라고 불리는 DB 쿼리의 실행 결과를 담는 경우다. 리포트 쿼리는 리포트를 출력하기 위해 생성하는 쿼리란느 의미인데, 단지 리포트를 위해서라기보단보통 종합 분석 리포트처럼 여러 테이블에 걸쳐 존재하는 자료를 분석하고 그에 따른 분석/통계 결과를 생성하는 쿼리라는 의미다. 이런 쿼리 결과는 DB 테이블에 담긴 필드의 내용보다는 그 합계, 평균과 같은 계산 값이거나 아니면 여러 테이블의 필드를 다양한 방식으로 조합해 만들어진다. 따라서 DB 쿼리의 실행 결과를 담을 만한 적절한 도메인 오브젝트를 찾을 수 없다. 그래서 이런 리포트 쿼리의 결과는 DTO라고 불리는 단순한 자바 빈이나 아니면 키와 값 쌍을 갖는 맵에 담아서 전달해야 한다.
때론 DB의 쿼리 하나로 최종 결과를 만들어내기 힘들기 때문에 코드를 통해 데이터를 분석하고 가공하는 작업이 필요하다. 이런 경우에도 최종 결과는 DTO나 맵, 컬렉션에 담겨서 전달돼야 한다.
때론 웹 서비스 등의 시스템과 자료를 주고 받을 때 전송 규약에 맞춰서 도메인 오브젝트에 담긴 정보를 가공해야 할 때가 있다. 이런 경우도 DTO나 맵을 이용해 형식에 맞도록 변경하는 작업이 필요하다.
3.4 스프링 애플리케이션을 위한 아키텍처 설계
지금까지 본 것 외에도 다양한 기술 조합과 업무조건, 시스템 환경에 따른 많은 결정요소와 변수가 있다. 그 중에서 계층 구조를 어떻게 나눌 것인가와 애플리케이션 정보를 어떻게 다룰지를 결정하는 것이 기본이 된다. 그리고 그 위에 각 계층에 사용될 구체적인 기술의 종류와 수직 추상화 계층의 도입, 세세한 기술적인 조건을 결정하는 일이 남았다.
계층형 아키텍처
3계층 구조는 스프링을 상요하는 엔터프라이즈 애플리케이션에서 가장 많이 쓰이는 구조다. 스프링의 주요 모듈과 기술만 살펴봐도 3계층 구조에 적합하도록 설계돼있다는 사실을 알 수 있다. 단, 3계층이란건 논리적이고 개념적인 구분이지 꼭 오브젝트 단위로 딱 끊어져서 만들어지는게 아니다. 때로는 계층이 다시 수평으로 세분화될 수도 있다. 반대로 3계층에서 두 계층이 통합돼서 하나의 오브젝트에 담기는 일도 얼마든지 가능하다.
예를 들어 서비스 계층을 굳이 도입하지 않아도 될 만큼 비즈니스 로직이 단순한 애플리케이션이라면 서비스 계층과 데이터 액세스 계층을 통합할 수도 있다. 스프링의 데이터 액세스 기술을 사용하면 복잡하고 지저분하게 반복되는 코드 대부분 제거되고 핵심 데이터 액세스 로직만 남은 간략한 코드를 가진 DAO를 만들 수 있다. CRUD같은 간단한 조건을 이용한 검색만으로 대부분의 기능을 수행할 수 있는 복잡하지 않은 애플리케이션이라면 서비스 계층을 데이터 액세스 계층에 통합하는 것도 나쁘지 않다. 이때는 트랜잭션 경계설정 위치를 DAO메소드로 삼으면 된다. 간단한 로직은 DAO에 넣어도 좋다.
반대로 프레젠테이션 계층에 서비스 계층을 통합하는 방법도 가능하다. DAO는 순수한 DB인터페이스 역할을 하는 데이터 액세스 기능만 갖게 하고 조건에 따른 간단한 로직의 적용은 프레젠테이션 계층의 컨트롤러에 넣는 것이다. 이 방법이 불가능하진 않지만 스프링에서는 그리 권장되지 않는다. 스프링 AOP를 이용해 트랜잭션 경계를 설정하기가 애매하기 때문이다. DAO가 트랜잭션 경계가 되는 경우에는 트랜잭션 전파 기법을 이용해 여러 개의 DAO 처리를 하나의 트랜잭션으로 조합해서 간단히 묶을 수 있다. 반면 프레젠테이션 계층의 오브젝트는 트랜잭션 단위로 삼기에는 너무 크고 트랜잭션 전파를 통해 조합하기가 애매하다. 그래서 굳이 이런 방식을 써야 한다면 TransactionTemplate을 이용해 코드에 의한 트랜잭션 경계설정을 해야 하는데 이는 너무 번거롭다.
따라서 3계층을 단순화해서 2계층으로 만든다면 서비스 계층과 데이터 액세스 계층을 통합하는 편이 낫다. 물론 이때도 논리적으로는 서비스 계층과 데이터 액세스 계층의 경계를 분명하게 하는 게 좋다. 같은 오브젝트에 담겨 있다고 할지라도 비즈니스 로직을 적용한다면 각각 독립적으로 메소드를 분리해두는 것이 바람직하다.
프레젠테이션 계층은 보통 MVC라는 이름으로 잘 알려진 패턴 또는 아키텍처를 주로 사용한다. 스프링의 대표적인 프레젠테이션 기술도 SpringMVC라는 이름을 갖고 있고, 이름처럼 MVC 패턴을 지원하게 되어 있다. 스프링은 이 MVC 중 가장 부담을 많이 지고 있는 컨트롤러에 해당하는 부분을 또 다시 세분화해서 여러 단계의 오브젝트로 만들 ㅅ주 있도록 설계되어 있다. 이런 식으로 계층 내의 역할을 좀 더 세분화하는 경우도 있다.
프레젠테이션 계층은 특히 그 경계를 애플리케이션이 배치된 서버를 떠나서 클라이언트까지 확장하기도 한다. SOFEA라고 불리는 아키텍처는 프레젠테이션 계층의 코드가 서버에서 클라이언트로 다운돼서 클라이언트 장치 안에서 동작하면서 서버에 존재하는 서비스 계층 또는 부분 프레젠테이션 계층과 통신하는 구조로 만들어진다. 브라우저 안에서 동작하는 자바스크립트나 플래시 기반의 애플리케이션을 포함해서 JVM이나 클라이언트 OS에서 독립적으로 동작하는 기술도 계속 발전하고 있다. 이때는 프레젠테이션 계층이 가졌던 사용자와의 인터페이스, 화면 흐름에 대한 제어, 서비스 계층과의 통신, 상태정보의 유지 등을 클라이언트에 다운로드된 코드에서 대부분 담당하게 된다. SOFEA는 전통적인 MVC 기반의 모델 2 아키텍처의 위치를 위협할 만큼 빠르게 성장하고 있다. 스프링 또한 이런 기술의 변화에 맞춰서 다양한 지원을 늘리고 있다.
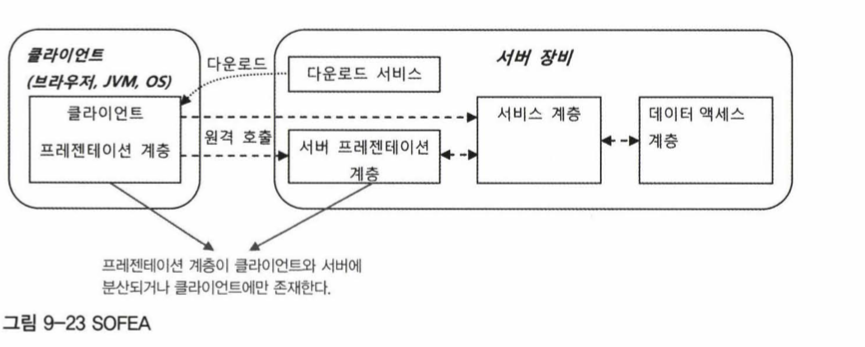
정보 전송 아키텍처
오브젝트 중심 아키텍처의 도메인 방식은 스프링의 기본 기술에 가장 잘 들어맞고 쉽게 적용할 수 있다. 일단 빈약한 도메인 오브젝트 방식로 시작하는게 제일 쉽다. 도메인 오브젝트를 계층 간의 정보 전송을 위해 사용하고, 이를 각 계층의 코드에서 활용한다. DAO는 그 기술이 어떤 것이든 상관없이 서비스 계층에서 요청을 받거나 결과를 돌려줄 때 도메인 오브젝트 형태를 유지하게 만든다. 서비스 계층의 비즈니스 로직 또한 도메인 오브젝트를 이용해 작성한다. 가능하다면 도메인 오브젝트에 단순한 기능이라도 추가하도록 노력해보는 것이 좋다. 프레젠테이션 계층에서도 이 도메인 오브젝트를 직접 활용하도록 만든다. 프레젠테이션 계층의 MVC 아키텍처에서도 모델은 도메인 오브젝트를 그대로 사용한다. 뷰에 전달하는 정보도 물론 도메인 오브젝트를 사용하는 모델이고, 사용자가 입력하는 폼의 정보도 도메인 오브젝트로 변환해서 사용한다.
이렇게 도메인 오브젝트를 사용해 애플리케이션의 정보를 일관된 형태로 유지하는게 스프링에 가장 잘 들어맞는 방식이다. 스프링에 포함된 예제나, 스프링 개발자들이 저술한 책에 나오는 샘플 애플리케이션, 그리고 스프링의 각 기술의 API 사용 방법을 살펴보면 거의 대부분 이 방식을 사용하고 있다.
객체지향적인 도메인 분석과 모델링에 자신이 있고 도메인 오브젝트 설계와 구현, 독립적인 테스트를 자유롭게 적용할 수 있다면 과감하게 도메인 계층 방식을 도입할수도 있다. 다만 도메인 계층에 DI를 적용하기 위해 스프링의 고급 기술을 활용해야 하고 여러 가지 고려할 점이 많으므로 충분한 사전 학습과 검증이 먼저 진행돼야 한다.
상태 관리와 빈 스코프
아키텍처 설계에서 한 가지 더 신경 써야 할 사항은 상태 관리다. 크게는 사용자 로그인 세션 관리부터, 작게는 하나의 단위 작업이지만 여러 페이지에 걸쳐 진행되는 위저드 기능까지 애플리케이션은 하나의 HTTP 요청의 범위를 넘어서 유지해야 하는 상태정보가 있다.
엔터프라이즈 애플리케이션은 특정 사용자가 독점해서 배타적으로 사용되지 않는다. 하나의 애플리케이션이 동시엔 수 많은 사용자의 요청을 처리하게 하기 위해 매번 간단한 요청을 받아서 그 결과를 돌려주는 방식으로 동작한다. 따라서 서버의 자원이 특정 사용자에게 일정하게 할당되지 않는다. 그래서 서버 기반의 애플리케이션은 원래 지속적으로 유지되는 상태를 갖지 않는다(stateless)는 특성이 있다. 클라이언트로부터의 요청을 처리하는 매우 짧은 시간 동안만 도메인 오브젝트와 같은 정보저장소에 현재 상태정보가 보관되지만, 이는 요청 결과를 클라이언트에 돌려주고 나면 바로 폐기된다. 그 덕분에 수많은 동시 사용자의 요청을 제한된 서버 리소스를 가지고 처리할 수 있다.
하지만 어떤 식으로든 애플리케이션의 상태와 장시간 진행되는 작업정보는 유지돼야 한다. 이를 위해서 웹 클라이언트에 URL, 파라미터, 폼 히든 필드, 쿠키 등을 이용해 상태정보 또는 서버에 저장된 상태정보에 키 값 등을 전달해야 한다. 클라이언트와 서버 사이에서 많은 양의 정보를 계속해서 주고받을 수는 없으므로 중요한 상태정보는 파일 시스템, 데이터그리드, DB 등에 저장되기도 한다. 또는 제약이 있기는 하지만 HTTP 세션과 같은 서블릿 컨테이너가 제공하는 저장공간을 활용하기도 한다.
이렇게 상태를 저장, 유지하는 데 어떤 방식을 사용할지 결정하느 일은 매우 중요하다. 스프링은 기본적으로 상태가 유지되지 않는 빈과 오브젝트를 사용하는 것을 권장한다. 웹의 생리에 가장 잘 들어맞고 개발하기 쉽기 때문이다. 또, 서버를 여러 대로 확장하기가 매우 쉽다. 반면에 웹 클라이언트에 폼 정보를 출력하고 이를 수정하는 등의 작업을 위해서는 HTTP 세션을 적극 활용하기도 한다. 대부분의 폼 등록, 수정 작업은 한 페이지짜리 폼이라도 여러 번의 HTTP 요청에 걸쳐 일어나기 때문에 작업 중인 폼의 내용을 짧은 동안에라도 서버에 저장해둘 필요가 있다.
상태는 클라이언트, 백엔드에 저장해두거나 서블릿의 HTTP 세션 정도에 일시적으로 저장해두는 것이 대부분이지만 경우에 따라서는 장기간 유지되며 중첩될 수 있는 상태를 다루는 고급 상태 관리 기법을 이용할 수도 있다. 애플리케이션 특징에 따라서 스프링을 이용해서 상태유지 스타일의 애플리케이션을 얼마든지 만들 수 있다.
스프링에서는 싱글톤 외에도 다른 스코프를 갖는 빈을 간단히 만들 수 있따. 빈의 스코프를 잘 활용하면 스프리이 관리하는 빈이면서 사용자별로 또는 단위 작업별로 독립적으로 생성되고 유지되는 오브젝트를 만들어 상태를 저장하고 이를 DI를 통해 서비스 빈에서 사용하게 만들 수 있다.
서드파티 프레임워크, 라이브러리 적용
스프링은 대부분의 자바 표준 기술과 함께 사용될 수 있따. J2EE 1.4, JavaEE 5.0을 지원한다. 따라서 JSP, JSF, EJB, JNDI, JTA, JCA, JAX-WS, JMS, JavaMail, JAP와 같은 JavaEE의 세부기술과 함께 사용될 수 있다. 스프링 애플리케이션은 기본적으로 서블릿을 기반으로 하는 독립 웹 모듈로 만들어진다. 스프링이 제공하는 많은 API는 이러한 표준 JavaEE의 인터페이스를 사용할 수 있도록 설계되어 있다.
표준 기술 외에도 많이 사용되는 오픈소스 프레임워크, 라이브러리나 상용 제품도 스프링과 함께 사용할 수 있다. 이런 기술을 스프링과 함께 사용할 때는 먼저 스프링이 공식적으로 지원하는 기술인지 확인해본다. 스프링의 의존 라이브러리로 등록된 100여 개의 각종 라이브러리를 살펴보면 스프링이 직접 API나 추상화 서비스 등을 통해 지원하는 표준 또는 오픈소스, 상용 기술에는 어떤 것이 있는지 알 수 있다.
스프링이 지원하는 기술이란 무슨 의미일까?
- 첫째, 해당 기술을 스프링의 DI 패턴을 따라 사용할 수 있다.
프레임 워크나 라이브러리의 핵심 클래스를 빈으로 등록할 수 있게 지원해주는 것이라고 생각해도 좋다. 코드를 이용해 초기화 해야만 사용할 수 있는 기능을 빈을 등록하는 것만으로 바로 사용할 수 있다. 프레임 워크의 핵심 오브젝트를 빈의 형태로 등록해둘 수 있다면 프로퍼티를 이용해 세부 설정을 조정할 수도 있고, DI를 통해 다른 오브젝트에서 손쉽게 활용할 수도 있다. 또 스프링이 제공하는 추상화 서비스를 통해 다른 리소스에 투명하게 접근할 수도 있다.
스프링 외의 기술을 접목할 때는 가장 먼저 스프링의 빈으로 등록해서 DI 방식을 통해 사용 가능한지 살펴봐야 한다. 만약 빈으로 등록해서 바로 사용할 수 있는 구조로 핵심 API나 클래스가 만들어져 있지 않다면, 위의 예처럼 스프링 빈으로 등록돼서 사용하기에 적합하도록 만들어주는 팩토리 빈을 도입해야 한다. 스프링이 지원하는 프레임워크나 라이브러리는 대부분 이와 같이 스프링 빈의 설정만으로 등록하고 사용 가능하도록 팩토리 빈 클래스가 제공된다.
- 둘째, 스프링의 서비스 추상화가 적용됐다.
이미 트랜잭션이나 OXM등의 예에서 다양한 오픈소스 프레임워크 또는 표준 기술에 대한 스프링의 서비스 추상화 기술을 살펴봤다. 첫 번째 방법은 사용할 기술을 스프링의 빈으로 등록하고 설정 가능하도록 지원해줬을 뿐이고, 사용 기술의 API는 애플리케이션에 그대로 노출한다. 서비스 추상화를 적용하는 경우는 이보다 한 발 더 나아가서 비슷한 기능을 제공하는 기술에 대한 일관된 접근 방법을 정의해준다. 이를 통해서 서드파티 프레임워크를 적용할 수 있을 뿐만 아니라 필요에 따라 호환가능한 기술로 손쉽게 교체해서 사용할 수 있다.
자바의 표준 기술이란 JCP를 통해 제정된 표준 스펙일 뿐이다. 다양한 벤더와 프로젝트 그룹이 이 스펙을 따라서 실제 구현을 만든다. 표준 스펙에 정의된 API를 이용해 개발하기만 하면 실제 기술의 구현 제품은 교환해서 사용할 수 있다.
이와 비슷한 원리를 다양한 비표준 기술과 영역에 확장해서 적용한 것이 바로 스프링의 서비스 추상화라고 볼 수 있다. 상세한 스펙을 따라서 엄밀하게 적용되는 표준과는 다르지만, 개발자에게는 표준 기술을 사용하듯이 일관된 방법으로 코드를 작성하게 해준다는 것은 중요한 의미가 있다. 스프링이 제공하는 서비스 추상화가 표준 기술 스펙과 다른것은, 서비스 추상화는 이미 존재하는 다양한 기술의 공통점을 분석해서 추상화를 했다는 점이다. 따라서 추상 서비스 인터페이스를 구현해서 각 기술과 연동하게 해주는 어댑터 클래스가 필요하다. 서비스 추상화 인터페이스를 구현한 클래스들은 모두 스프링의 빈으로 등록되도록 만들어졌고, 세부 기술의 특성에 맞는 설정이 손쉽게 가능하도록 다야한 프로퍼티를 제공하고 있다.
- 셋째, 스프링이 지지하는 프로그래밍 모델을 적용했다.
스프링이 지지하는 프로그래밍 모델이 적용된 대표적인 예는 스프링의 데이터 액세스 기술에 대한 일관된 예외 적용이다. 스프링의 데이터 액세스 지원 기능을 사용하면 데이터 액세스 기술의 종류에 상관없이 일관된 예외 계층구조를 따라서 예외가 던져진다. 여기에는 기술에 독립적인 DAO를 만들 수 있도록 데이터 액세스 예외를 추상화하고, 불필요하게 예외를 처리하는 코드를 피하도록 런타임 위주의 예외를 사용한다는 스프링의 개발철학이 적용된 것이다. 이를 통해, 서비스 계층의 비즈니스 로직을 담은 코드가 데이터 액세스 계층의 기술에 종속되지 않도록 만들어준다.
- 넷째, 템플릿/콜백이 지원된다.
스프링은 JDBC, JMS, JCA를 비롯한 20여 가지 기술을 지원하는 템플릿/콜백을 제공한다. 이런 기술은 그대로 사용하면 반복적으로 등장하는 판에 박힌 코드 때문에 전체 코드가 지저분해지고 이해하기 힘들고 추상화하기도 어려운 구조가 돼버린다. 스프링은 이런 기술을 간편하게 사용할 수 있도록 템플릿/콜백 기능을 제공한다. 대부분의 템플릿 클래스는 빈으로 등록해서 필요한 빈에서 DI 받아 사용할 수 있다.
스프링이 어떤 기술을 지원한다는 건, 결국 스프링이 지지하는 개발철학과 프로그래밍 모델을 따르면서 해당 기술을 사용할 수 있다는 의미다. 물론 이런 방법을 따르지 않고도 스프링에서 여타 프레임워크를 사용하거나 라이브러리를 이용할 수는 있다. 그 대신 스프링의 장점을 포기해야 하고, 일관된 구조의 유연하고 확장 가능한 코드를 만들기가 힘들 수 있다.
물론 스프링이 세상에 나와 있는 모든 기술과 프레임워크를 지원하진 않는다. 스프링이 직접 지원하는 수십여 가지의 표준, 오픈소스, 상용 기술은 엔터프라이즈 애플리케이션 개발에 보편적으로 사용되는 유명한 것들로 제한된다. 대신 스프링의 기술 지원 방법은 스프링의 핵심 기술과 프로그래밍 모델만 잘 이용하면 어떤 기술이든지 손쉽게 적용이 가능하다. 따라서 스프링이 직접 지원하는 기술이 아니라도 앞에서 소개한 네 가지 방법을 따라서 사용하도록 만들 수 있다.
스프링 익스텐션(www.springsource.org/extensions)은 스프링이 직접 지원하지 않지만 나름 유용한 기술에 대해 스프링 스타일의 지원 기능을 만들어둔 대표적인 프로젝트다.
스프링에 새로운 기술을 연동하려면 이 책에서 설명했던 스프링의 프로그래밍 모델과 지지하는 개발철학을 따르면서 앞에서 설명한 네 가지 방법을 이용하면 된다. 가장 기초는 스프링의 빈으로 해당 기술의 핵심 오브젝트가 등록되도록 만드는 것이다. 필요에 따라 팩토리 빈을 사용해서 오브젝트 생성과 초기화 작업, 프로퍼티 노출 등을 해줘야 한다. 애플리케이션 내의 빈들이 새로운 기술에 대해 빈을 DI 하는 방법으로 접근할 수 있게 하는것이다. 반대로 기존 빈 오브젝트를 새로 추가할 기술에서 사용할 수 있게 해줄 필요도 있다. 어떤 경우든 코드에 의한 초기화 작업이 필요하므로 팩토리 빈을 만들어 사용하면 편리하다.
때로는 서비스 추상화를 시도할 경우도 있다. 어떤 경우는 스프링이 이미 제공하는 추상 인터페이스의 새로운 구현으로 만들어질 수 있고, 아예 새로운 추상화 인터페이스를 정의해서 적용할 수도 있다. 특히 JavaMail처럼 테스트가 매우 까다롭게 설계된 기술이고 DI 해서 상요하기 불편하다면, 유연한 설정과 더불어 테스트를 위해서라도 새로운 인터페이스를 추가할 필요가 있다.
네트워크 접근이나 파일 IO처럼 실패할 가능성이 있는 시도를 하는 기술이라면 템플릿/콜백 방식의 적용도 적극 고려해보자. 기술을 사용할때마다 반복적으로 try/catch/finally 블록이 필요한 기술이라면 템플릿/콜백이 제격이다.
때로는 AOP나 예외 전환을 적용할 수도 있다. 보통 외부에서 가져와서 사용하는 기술은 내부 구현 방식에 손을 대기 쉽지 않다. 소스코드가 공개되고 수정이 가능한 오픈 소스라고 할지라도 코드를 한번 손대기 시작하면 이후 버전과 호환성이 떨어지기 때문에 함부로 수정해서 사용하기는 힘들다. 따라서 가능하면 외부 기술의 코드에는 손을 대지 않고 사용 방법을 개선하는 작업이 필요하다. 예외 변환은 종종 AOP를 통해 많이 이뤄진다. 특정 예외가 던져졌을 때에 대한 포인트컷을 만들어두고 어드바이스에서 예외 추상화된 런타임 예외로 바꿔서 다시 던져주면 된다. 그러면 해당 API를 ㅅ용하는 코드를 전혀 손대지 않고도 손쉽게 예외 변환이 가능하다.
스프링이 직접 지원 기능을 제공해주지 않으면 무엇인가 시도해볼 생각도 없이 스프링 이전의 방식대로 코드를 만들어서 외부 기술을 사용하는 건 부끄러운 일이다. 스프링을 사용하려면 스프링의 프로그래밍 모델과 그에 담긴 개발 철학을 따르는 일관된 코드를 만드는 데 많은 관심을 기울여야 한다.
'Spring > 개념' 카테고리의 다른 글
| Void Type (0) | 2023.12.28 |
|---|---|
| [토비의 스프링1] 8 스프링이란 무엇인가? (0) | 2022.06.27 |
| [토비의 스프링1] 7.2 인터페이스의 분리와 자기참조 빈 (0) | 2022.06.26 |
| [토비의 스프링1] 7.1 SQL과 DAO의 분리 (2) | 2022.06.26 |
| [토비의 스프링1] 7 스프링 핵심 기술의 응용 (0) | 2022.06.26 |